近年來網際網路的風行,帶動整個通訊網路工業的發展,國內所擅長的製造技術,使不少通訊網路廠商在國際市場上佔有一席之地。在整個網路通訊業中,國內較擅長的領域,仍是屬於較偏用戶端的網路卡、數據機等,及區域網路的設備如集線器、交換器等。乙太網路已是目前區域網路的主流技術,而交換器由於提供成倍的網路頻寬,在ASIC技術不斷突破下,成為技術開發的重點。因成本不斷降低,可望成為將來建構網路的唯一基礎設備。目前國內已有多家廠商投入交換器晶片、系統的設計,功能上朝向高頻寬、多層次、高功能發展。本文嘗試由乙太網路的技術發展軌跡,介紹交換器的由來及所謂多層次的觀念與各種相關功能的關係,希望能使讀者對交換器有較完整的了解。
資料通訊的標準,根據國際標準組織(ISO)所制定的開放系統互連模型(Open Systems Interconnect,OSI),包含七個層次,即實體層(Physical Layer)、資料鍊層(Data-Link Layer)、網路層(Network Layer)、傳輸層(Transport Layer)、會談層(Session Layer)、展示層(Presentation Layer)、應用層(Application Layer)。其中愈低層者與網路設備的關聯性愈大,較高層者則與用戶端的軟體功能有關。一般資料通訊設備大多處理下三層,即實體層、資料鍊層及網路層,就乙太網路而言,實體層的設備為集線器(Hub),資料鍊層的設備為橋接器(Bridge),或第二層交換器(Layer 2 Switch),而網路層的設備為路由器(Router),或第三層交換器(Layer 3 Switch)。高附加價值的網路設備則嘗試監控更多層次的資訊,號稱第四層,或更高層的設備。
乙太網路簡介
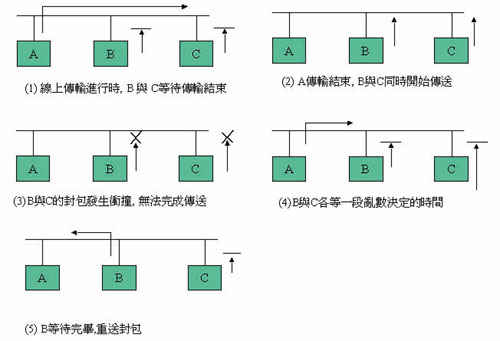
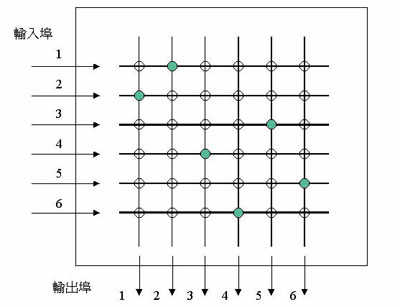
乙太網路是廣播型態的區域網路,最初的型態是將各節點用收發器(Transceiver)接在一條同軸電纜上,各點之收送順序則以一套公平競爭的協定決定,所謂CSMA/CD(Carrier Sense Multiple Access with Collision Detection),其方式為同一纜線由多點共用,欲傳送資料時各自偵測纜線上是否已有資料傳送中,而若無載波或待載波停止後即開始傳送,此即載波偵測功能,但其時假若有其他節點也要傳送,就發生碰撞而導致資料損毀而失敗,此時碰撞檢測即發現此狀況,準備將資料封包重送,但先等一段由亂數決定的時間再送,以避免與同一對象再次碰撞。CDMA/CD為一種極簡單的機制(圖一),可使數以百計的節點在一個網路上收送資料,而不需任何特定的網路管理站協調管理。此機制與主要競爭對手權仗環網路(Token Ring)相比,在在顯示其低成本及易使用的特性,從而終於席捲區域網路的市場,成為優勢的技術。
乙太網路既為多點廣播的網路,在資料封包送出時必須能含有位址資訊,以指定接收對象(圖二)。封包發出後所有同一電纜上的所有節點都會收到,而每點的電路會將此目的位址與本身位址比對,僅有發送對象會將封包收下,而其他節點會將其丟棄。乙太網路的位址為6個位元組。在訊頭中前6位元組為目的位址(Destination Address),即傳送對象的位址,次6位元組為來源位址(Source Address),即發送點的位址。此位址是由設備廠商設定,每一連接埠需保證其為唯一,以避免重複而造成衝突,而發放位址的單位為制定乙太網路標準的電子電機工程師協會(IEEE),乙太網路的標準編號為IEEE 802.3。
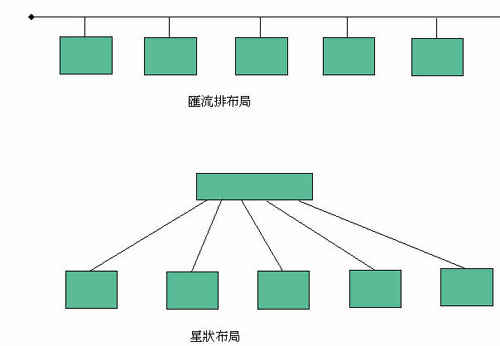
乙太網路的發展經過幾次重大變革,首先雙絞線(Twisted Pair)10BASE-T技術的發展,改變了網路佈線的型態。雙絞線技術必須利用主動設備-集線器(Hub),而不是單純的電纜,而且電纜以點對點一一布設,而非串接,表面上都增加成本,然而點對點以集線器為核心的星狀佈局(圖三),可平行於電話線佈設,由牆壁插座引出,在大樓中較串接的同軸電纜方便,而且集線器可提供網路管理功能,使雙絞線成為此後乙太網路的主流。在雙絞線架構中,碰撞的機制是由集線器提供的,所以CSMA/CD的特性仍然維持。
乙太網路的速率也有驚人的成長。在乙太網路初期有1Mbps及10Mbps。其後10Mbps成為標準數年,接著100Mbps的技術出現,速率以10倍成長,不久後1Gbps(1000Mbps)標準完成,目前已在討論10Gbps,而也有人已在提議100Gbps。
另一個變化是橋接器(Bridge)的出現。最初的乙太網路由同軸電纜及增益器(Repeater)構成,由於電波傳導的速率及CSMA/CD時序的限制,網路的範圍局限於2500公尺內。而網路節點數受CSMA/CD競爭機制的影響,不可能太多,否則隨機碰撞將耗損所有的頻寬,癱瘓整個網路。最初乙太網路標準估計,節點的上限是1024。
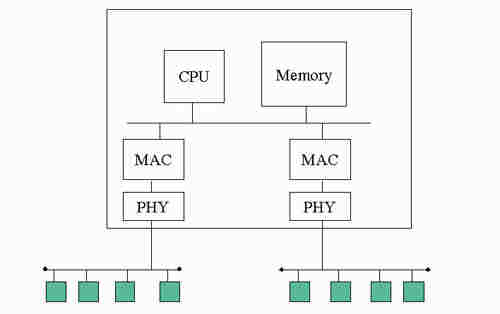
橋接器的發明解決了這些問題。最簡單的橋接器構想如(圖四)所示,是一個雙埠的主動設備,中心為一微處理器,由於乙太網路的廣播性質,所有纜線上傳遞的封包都可以由一埠接收,而由處理器在另一端送出。如此形成一個第二層(Layer 2)的增益器。由於封包由另一端送出相當於一個節點重新在電纜上發送,網路的範圍可擴大一倍。經由多個橋接器,網路可以擴展到相當大的範圍。然而橋接器本身的處理,及封包的收發免不了造成一些延遲,累積後對上層協定的運作會有影響,所以擴展的範圍也會有限制。標準的建議是網路的直徑不超過6個橋接器。橋接器的觀念在每一個區域網路標準都有,所以是由IEEE的另一工作組所規定,標準編號為IEEE 802.1D。
解決節點數的問題則較複雜。為維持乙太網路的簡單特性,橋接器的構想是透通的(Transparent),意即可做到即插即用(Plug-and-Play),而不須任何設定的動作。觀察橋接器兩端的資料流,可發現相當比例的本地化傾向,即傳送來源及對象都屬於同一端。假如能對這些封包作出判斷,不將其轉送,就可以大幅降低不必要的交通量而有效提升兩端能支應的節點數。然而達成此點的技術相當複雜,也是日後交換器設計的關鍵所在。
判斷封包的目的位址的節點位置,首先必須建立一個位址表來查詢。由於必須具備透通性,此位址表不能要求用戶來設定,而須由網路的運行得來。所以方法是在轉送封包時將來源位址記下,填於位址表中,等下次同一位址出現於封包目的位址欄時便可作正確的判斷。於是標準的乙太網路橋接器具有以下功能:
- (1)學習(Learning):將封包內的來源位址及封包的輸入埠存於位址表中。
- (2)過濾(Filtering):將封包內的目的位址與現有位址表比對,若發現已存在,且其輸入埠與新封包的輸入埠相同,證明該目的位址與來源位址所屬的節點都存在橋接器的同埠位置,無須加以處理,於是將該封包丟棄。
- (3)轉送(Forwarding):若目的位址的節點位於另一埠的位置,則應將封包由該埠送出。
- (4)溢流(Flooding):若目的位址不存在位址表中,則該位址可能錯誤,或太久未使用,或新開機尚未傳送過,無論如何,為達成透通性,應將封包向來源埠以外的所有埠送出,若該節點真正存在,即可收到該封包。
- (5)老化(Aging):橋接器是永續開機的網路設備,位址表經由不斷學習,會逐漸增長,其中若有錯誤、更換、經常關機、偶而使用的外來節點等佔據位址表,會將位址表填滿,妨礙新的節點位址的學習動作,所以位址表內的有效位址均設定一定的時效,除非不斷被使用而重設時限,否則時限到就會移除。
此一連串的處理程序有兩種動作是關鍵:
- (1)封包的接收及傳送:須將資料依序存入記憶體內,再依序讀出。資料的量決定記憶體的頻寬需求,及搬運資料的處理能力需求。隨乙太網路頻寬的不斷上升,及橋接器埠數的增加,這種需求有增無減。
- (2)查表的效率:查表是基本的演算法之一,查表所需時間與所用演算法及表的大小有關。一般而言,橋接器的位址表是以千計的,而在此大小下,不同的演算法會有很大的差別。如按順序搜尋(Sequential Search),其所需時間為O(n),即與表的大小成正比例,好一點的如二元搜尋法(Binary Search) ,所需時間為O(log n),即與表大小的對數成比例。如以散列法(Hashing),則所需時間約為常數,與表的大小無關。
處理封包時間的原則是,一個封包所需的動作必須在下一個封包完全接收到以前完成,否則以後的封包會丟失。乙太網路封包的長度規定最短為64位元組,而封包之,以10Mbps而言,一個封包允許的處理時間有67.2us(67.2x10-6sec),100Mbps則僅有6.72us(6.72x10-6sec)。至於在1Gbps下,僅有672ps(672x10-9sec)。即便是10Mbps下,普通的微處理器系統利用最好的演算法也無法同時應付許多埠的封包處理需求。
微處理器是一種為一般運算所設計的電路,即使是簡化的RISC處理器也有極複雜的結構,應付如此大量的重複處理工作並非所長,而多埠橋接器的處理需求已非單一微處理器的系統所能負荷。稍作簡單計算即可了解:假如微處理器的時脈為100MHz,每一脈衝處理一個指令,則約略一個指令執行時有一個100Mbps埠的位元被接收。一個最短封包(64位元組=512位元)連前導訊號(Preamble)64位元及必需的封包間距(Interframe Gap)96位元,共672位元,即672指令內需處理完成,而兩埠則每封包僅有336指令,更多埠則再遞減。對微處理器系統運作稍有了解者都知道,接收及處理封包都需要很多指令的動作,系統軟體及中斷機制等有許多效率耗損,一個微處理器絕對處理不了幾個埠,更何況橋接器又有許多網路管理功能,也需要一定的處理效能。
以特殊的硬體線路輔助處理大量封包,是很自然的發展。首先,利用直接記憶體存取(DMA)線路代替微處理器指令搬封包資料是最直接的方法。查表的動作可用內含定址記憶體(Content Addressable Memory;CAM)一種特殊的記憶體,可輸入內容反查其位址)來處理。CAM至今仍為高級網路設備常用的的線路,但由於成本高,一般的設計多不採用。
利用特殊設計的硬體線路來設計多埠橋接器(Multiport Bridge)的構想就逐漸成形。這種設備就被稱為乙太網路交換器(Ethernet Switch)。名為交換器的原因是引用電信交換機的聯想,而與微處理器系統的橋接器區隔。或問為何不用大量微處理器來克服效能障礙呢?答案是可以,但微處理器仍要特殊設計,這就是目前熱烈討論的網路處理器(Network Processor),原因是微處理器成本高,又需記憶體儲存程式及資料,以及一些周邊電路,不僅不經濟,且設計上也困難重重。即使是網路處理器也必須克服成本的問題。
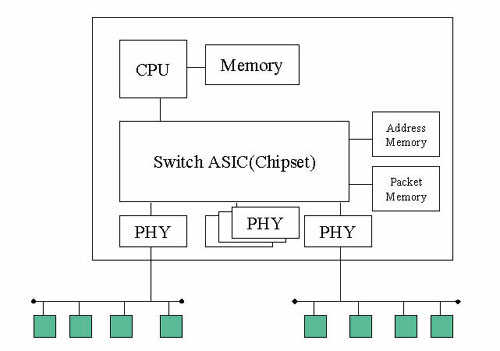
乙太網路交換器的系統架構如(圖五)所示,由一組特殊設計的交換器晶片為核心,交換器晶片須利用兩種記憶體,一種儲存封包內容,一種儲存位址表。提供網路管裡功能的交換器仍有微處理器,但僅用於提供網路管理功能,封包處理由交換器晶片負責。
交換器晶片處理封包完全根據原有的橋接器原理執行,動作極複雜,而晶片內也包含標準的乙太網路媒介接取層(MAC Layer)電路,所以設計上並不容易。
最初交換器設計有所謂直通(Cut-through)模式,即封包接收一部份後即開始發送至另一埠,通常是目的位址查表完成,知道輸出埠後,這種方式可以降低延遲時間。近期則不再強調,而都採取先存後送(Store and Forward)模式。原因是現在的交換器各埠的速率可能不同,可為10Mbps,100Mbps,或1Gbps,不同的速率不能用直通法。而且封包內容若到最後檢核有誤,本應直接丟棄,但前段內容已送出,無法挽回,不但增高網路錯誤率,連送出埠是否正確都無法確定,所以直通法已不再採用。
交換器的位址處理多採取散列法(Hashing),有些也利用CAM。與微處理器系統不同是散列法無法避免衝撞,即不同乙太網路位址對應到同一陣列指標(Index),競爭同一儲存位置。微處理器程式的處理法是將衝撞的個體用指標(Pointer)連成一串,以後沿指標依序比對。但交換機晶片硬體設計不可能如此細膩,而且交換器設計以一定時限完成為原則,不可能沿指標無限搜尋下去。折衷的辦法是設計數層陣列,即能包含如數的衝撞機會。萬一發生衝撞的個體超過層數,則可犧牲較不常用的一個。
由於不存在或被剔除的位址是以溢流(Flooding)處理,不會影響使用者。最壞的情況是衝撞的各位址都不斷出現,溢流不斷發生,相當於有大量的廣播(Broadcast)封包,使整個網路的效能大幅降低。所以散列函數(Hash Function)的選擇十分重要,須在任何常見的情境中均能有完全散亂的分布。交換器晶片的散列函數設計如太簡單,往往在標準測試組合下就發生溢流,造成效能數據偏低,雖然在真實環境不見得會發生,但對產品而言是十分不利的。
利用散列法的另一個缺點是保留的陣列大小無法充份利用,而且在使用的空間逐漸增加時溢流的機率會逐漸增加,到近填滿時幾乎每一個新位址都會衝撞,而且無法預測何時會發生溢流,除非網路管理者知道交換器的散列函數,又知道每一個乙太網路位址,預先加以防範,但這是不可能的要求。要減低這種效應的方法是儘量加大位址表空間,使其遠大於一般網路的需要。採用CAM可充份運用每一個位址表空間,而且在完全填滿前不會溢流。目前由於成本因素僅在高階的產品見到,未來若ASIC技術進展到能使交換器晶片能直接包含夠大的CAM部件,則使用CAM會是一個較理想的方式。
交換器晶片能支應的埠數也是一個重點。交換器的設計有兩種主要方式,一為共享記憶體(Shared Memory),另一種為縱橫交換器(Crossbar Switch)。共享記憶體為傳統微處理器系統架構的類型,只是用硬體電路處理封包,能支應的埠數由硬體的效能決定。一般而言,邏輯電路較容易設計支應高頻寬,所以頻寬的要求在記憶體上。每一個封包需兩次處理,一次因接收而存入,另一次因發送而讀出,所以100Mbps的埠需要200Mbps頻寬。8埠交換器需要1.6Gbps頻寬,24埠需要4.8Gbps,1個1Gbps埠需要2Gbps,依此類推。由一組交換器晶片的埠數可直接推出其封包記憶體的設計需求。由於記憶體能支應的頻寬是固定的,高頻寬可加寬記憶體的位元寬度來設計,如用128位元寬度可處理32位元寬度的4倍頻寬。位址記憶體的頻寬要求視位址表的結構而定,大體而言,其設計約與封包記憶體同等級。
如果記憶體的頻寬低於埠數的需要,則該交換器晶片的設計無法達成線上速度(Wire Speed),即無法讓所有的埠用全速運作。這種設計在低成本的情況下可能被接受,因為一般網路不可能隨時所有埠以全速運作。以往傳統的兩埠橋接器無法達成線上速度的也所在多有。若頻寬需求在運作時被超越,可能的處理方式為:
- (1)丟棄新接收的封包,由上層協定自行重送。
- (2)以流量控制(Flow Control)法減低輸入速度。
由於個別埠的輸出頻寬在一般情況下也可能發生超載的現象,例如許多埠同時向單一埠轉送,所以流量控制及丟棄法都是交換器應處理的情況。
共享記憶體的設計有其瓶頸,頻寬不可能無限加大,記憶體加大位元寬及提昇頻率,都會增加成本及設計難度,所以需要找到更經濟的方式來提高埠數。
(圖六)顯示一個縱橫交換器的設計。各埠或各組共享記憶體的埠獨立處理其封包,中心為一縱橫交換器。縱橫交換器的設計最簡單是由多工器(Multiplexer)組成的交換陣列,藉由控制訊號打開陣列的交叉點接通線路,如果不同的輸入埠同時希望接通不同的輸出埠時就可以有效運用所有的頻寬。這種設計十分類似電信交換機的線路交換(Circuit Switch)技術。由於縱橫交換器的設計可以用較低的成本達成很高的效能,所以是交換器設計中常用的技術。
或問為何不都用縱橫交換器?封包記憶體及位址記憶體都是很高的成本負擔,在經濟可行的設計範圍內讓更多埠共享是較有利的。縱橫交換器還有其特殊的瓶頸問題,即列頭阻塞(Head-of-Line Blocking),由於其下層晶片都必須將封包排隊以通過交換器,若第一個封包的出路阻塞,就會妨礙其後向其他未阻塞出路的封包的通行,所以運用縱橫交換器是一種設計上的取捨。高埠數交換器的設計往往是這兩種設計的混合,如以共享記憶體能以較經濟方式達成的最高埠數為基礎晶片,再用縱橫交換器層疊以提高埠數。
另一種設計是環路設計,其原理有如權杖環網路(Token Ring),如圖所示。其核心為一高速的環狀骨幹,封包循環運行後到達目的晶片後送出。環路的設計很有彈性,如各晶片的頻寬總和小於骨幹速率時系統可達線上速度,若將更多交換晶片組成環,可設計出超載的系統。但環路設計的封包須循環路前進,可能有較多瓶頸。
乙太網路的發展歷史為解決網路的種種問題,發展出各種特殊的功能,以下將較重要的列出,以為交換器設計的參考:
全雙工(Full-Duplex)
乙太網路最初的CSMA/CD法則,是半雙工的(Half-Duplex),即送與收不能同時進行,這是因為多點(Multipoint)網路本來同時只能有一家發送。在交換器成為主流後,全雙工的方式成為可能,而標準也迅速定出。交換器的埠直接連接節點或另一交換機埠,由於對家只有一個節點,沒有競爭問題,可以忽略CSMA/CD法則,允許送收兩線獨立運作,而達成全雙工運作。
全雙工的線路頻寬等於半雙工的兩倍,又省略CSMA/CD,簡化電路設計。另一個最大好處是CSMA/CD協定為協調多點的送收,設定一些時序的限制,即必須考量訊號必須在最短封包傳送完畢前到達最遠節點,否則無法及時作出正確的衝撞動作,而訊號的傳遞速度上限為光速,結果是網路的直徑及每一連線的長度都必須設定限制,而媒介接取層(MAC Layer)的電路的設計也須十分注意。全雙工設計取消CSMA/CD,也解除大部份限制,例如半雙工CSMA/CD的個別線路一定有長度限制,也有集線器個數的限制,但全雙工線路沒有絕對的長度限制,多半取決於信號衰減的程度,所以有可能拉上數公里,甚或幾十公里,使乙太網路突破區域的限制,侵入都會網路(MAN)及廣域網路(WAN)的領域。
在100Mbps的時代,半雙工的技術已達極限,網路的布局設計已經有很大的限制。在1Gbps乙太網路的制定初期尚考慮半雙工的技術,但標準的時序限制已不可能支應合理的線長,因此標準本身作一些修正,例如規定最短封包為512位元組,而非64位元組。但發展的結果半雙工技術逐漸被放棄,而1Gbps乙太網路目前僅有交換器產品,而無集線器了。將來的10Gbps或更高的速率,一定只會有全雙工的模式。可見的將來交換器的成本將逐漸降低,而終於取代所有的集線器,CSMA/CD也將成為歷史。若問乙太網路除去CSMA/CD,還剩甚麼?答案是標準的封包格式,包含封包長度、位址格式等。這也是乙太網路的最大資產。
自動協商(Autonegotiation)
乙太網路的發展產生許多變形,在同一電纜的兩端往往有速率的不同,全雙工或半雙工的設定等,最初都是人工設定以達成一致,後來為實際需要,逐步發展出兩端自動協商的機制,係利用實體層的特殊訊號交換彼此的能力,而協調出最佳的速率及雙工的匹配。交換器晶片不必處理自動協商,那是實體層(PHY)晶片的事。但必須知道協商的結果如埠的速率、雙工模式及流量控制設定等事項。
擴張樹協定(Spanning Tree Protocol)
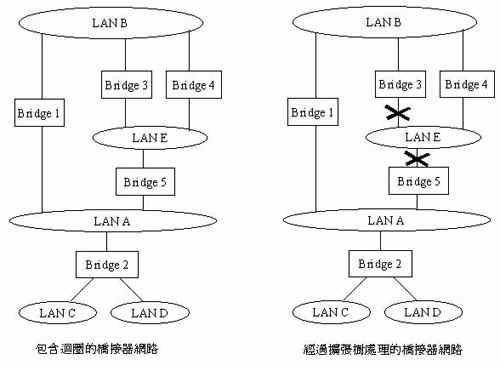
在橋接器發展的初期就發現一個問題,就是橋接器形成的網路不可有迴圈。本來在集線器的網路也不可有迴圈,否則訊號來回重覆傳遞,馬上癱瘓整個網路,但集線器有一個Jabber保護機制,可以自動關閉有問題的埠,保持整個網路的正常運作。橋接器是屬於網路第二層的設備,必須利用控制封包來解決,而無法直接用硬體電路。迴圈造成的問題之一是橋接器處理廣播及溢流封包,是向輸入埠以外的所有埠發送,若網路有迴圈,該封包就會循另一條路徑回到原發送之橋接器,而被反覆轉送無限次,進而癱瘓整個網路。
網路迴圈的問題十分難查,只要有一個小地方有個本地迴圈,整個網路就被廣播風暴(Broadcast Storm)所席捲。為解決此問題,發明了擴張樹協定(Spanning Tree Protocol)。擴張樹是圖學(Graph Theory)的一種觀念(圖七),是指在一個由點和線組成的圖形中,移去若干線來除去所有的迴圈,使每一點能有路徑到達任意點,而且路徑為唯一。剩下的點線構成一個樹狀圖。擴張樹協定使每一個橋接器利用此協定與其他橋接器交換資訊,自動使整個網路形成一個擴張樹,而除去所有迴圈。
乙太網路交換器既為橋接器的一種,也必須提供擴張樹的功能。擴張樹協定本身是由微處理器執行,但配合協定的執行,每個埠必須有阻塞(Blocking)、傾聽(Listening)、學習(Learning)、轉送(Forwarding)等狀態,影響封包收送及位址表之處理等動作,這是交換器晶片必須提供的功能。
流量控制
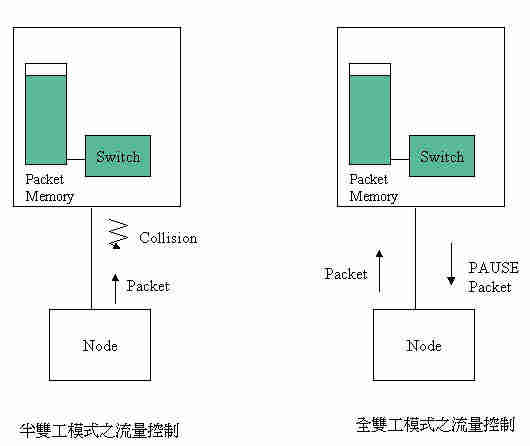
標準的CSMA/CD協定沒有流量控制,封包送出後直接由接收節點收下,該節點若不勝負荷,上層的協定會處理。集線器是實體層的設備,沒有緩衝器(Buffer)將封包收下,也無從控制流量。交換器的動作是將封包收下後轉送,如果轉送的速度不及接收的速度,或有其他埠競爭同一輸出埠,則封包會在封包記憶體內快速累積。在封包記憶體用完之前,可以作流量管制,否則記憶體用完後,新接收的封包只有丟棄一途。
在半雙工的埠,流量管制用模擬衝撞(Collision)的方式達成,即將流入的新封包加以衝撞,使其進入後退模式(Backoff),而達到減緩輸入的效果(圖八)。全雙工的埠無衝撞功能,在全雙工標準IEEE802.3x中定出用控制封包的方式作流量管制,即由接收端發出表示暫停的封包,送端即停止傳送一段時間。收端在有空間時亦可主動送出封包要求再送。交換器具有流量控制功能者必須有這些動作。
虛擬網路(Virtual LAN)
為實用的需要,多埠的交換器往往具備分組的功能,即將一個交換器的所有埠分為互不相連的幾組,各組內可以互通,但組之間不互通。每一組形成一個單獨的區域網路,如此分區的主要用途是將每一區定為一個子網路(Subnet),再用路由器(Router)聯絡各子網路,形成公司網路,或稱內網路(Intranet),而經對外的路由器連上網際網路(Internet)。
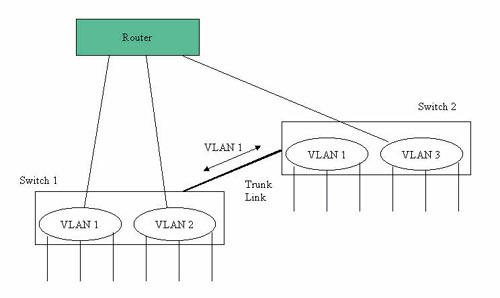
埠的分組後來又稱為虛擬網路(Virtual LAN;VLAN),其實虛擬網路的種類有相當多種,視分類的標準而定,如有以埠分組的虛擬網路(Port-based VLAN)、以乙太網路位址分類的虛擬網路(MAC-based VLAN)、以子網路分組的虛擬網路(Subnet-based VLAN)、以協定分類的虛擬網路(Protocol-based VLAN)等。以埠為主的虛擬網路較簡單,也有IEEE802.1Q標準規定之。在此標準中特別定了一個新的標籤(Tag)欄,將乙太網路的最大封包長度擴充4個位元組,至1522位元組。標籤中包含一個12位元的虛擬網路識別碼(VLAN ID),使虛擬網路可以辨識。
為何需要虛擬網路標籤?由(圖九)可得知。原來埠的分組僅限於一台交換器內,如果一個子網路所需的埠數超過一台交換器,或為設定方便希望將一個子網路分別定在兩台交換器中,如何作到?只要將相同的虛擬網路識別碼設定在兩台交換器的兩個虛擬網路,將兩台交換器的連接埠設為加標籤的主幹鍊結(Trunk),則封包到另一台交換器後可自動送到相同的虛擬網路中,將兩台交換器的相同虛擬網路連為一氣。
服務品質(Quality of Service)
乙太網路的缺點及優點都是其公平性。在CSMA/CD網路上所有節點都是平等的,沒有誰有優先權。最近多媒體的應用則生出新的需求,希望將應用加以分類,有些資料沒有時效性,可以等待交通順暢時再送,另一些則要求時效性,如即時的聲音傳遞,需要定時送出,不能延遲,所以收到聲音封包後,必須優先處理。由於交換器內部有佇列(Queue)排定封包送出的順序,可以作某些優先權的功能。在上述的虛擬網路標籤中有3個位元可表示優先權。不同優先權的封包可置入不同的佇列中,由高優先權的佇列優先送出。每一種優先權在每埠都需要一個佇列。例如某交換器可提供四類優先權,表示每埠至少有四個輸出佇列。
交換器能處理優先權者可以支應基本的多媒體通訊需求。
群播(Multicast)
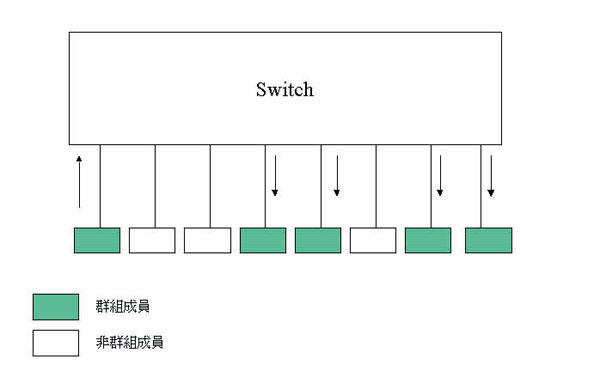
群播是利用特殊的目的位址,將封包送給一群對象,而非單一節點。廣播(Broadcast)是最常用的一種群播,所有節點均須收下廣播封包,再判定是否包含需要的資訊。由於廣播會使所有節點疲於奔命,其使用必須十分節制,所以需要一群節點同時接收的資訊多用非廣播的群播來發送,節點內的電路可以自行判定是否接收特定的群播位址,而不會接收不必要的資訊。乙太網路的特性十分適合群播,因為封包發出後,會送給所有節點,各節點由目的位址判斷是否接收。群播的封包假如改用個別發送,則佔用的頻寬會是群組成員數的倍數。早期廣播及群播僅用於高層協定建立最初連繫的工具,或伺服器、路由器等廣播網路管理資訊等,所佔頻寬不大。然而多媒體應用崛起後,群播被視為即時影音廣播的利器,則所佔的頻寬會影響網路的運作甚巨。
交換器處理群播,最先仍採取廣播的方式,即收到群播封包後以溢流的方式發出(圖十)。但若群組的成員不多,這種方式相當不經濟,所以後來定出群播註冊的方式,即參與群播的節點發出註冊通知,交換器收到後即知該埠有群播成員,每一交換器的成員名單再以廣播的方式通知所有的交換器。當群播封包收到後,交換器只會將該封包發送到含有群播成員的埠。目前群播功能在第二層有GMRP協定,第三層有IGMP、DVMRP、PIM等協定,負責群組的註冊與傳播。交換器亦有提供IGMP窺探(IGMP Snooping)功能,即藉捕捉第三層群播註冊的IGMP封包,來設定本身的群組成員。群播功能與封包轉送有關,交換器晶片必須有此設計,系統纔能支援此功能。
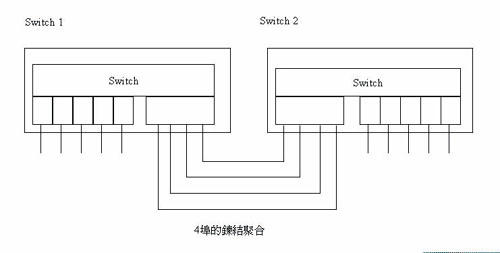
鍊結聚合(Link Aggregation)
在擴張樹協定中,平行的鍊結視為迴圈而藉阻塞(Blocking)狀態移除多餘的鍊結,使兩交換器間僅有單一鍊結,而避免封包繞圈的問題。多餘的鍊結僅作後備用途。如此一來相當於浪費許多頻寬。為有效利用平行鍊結的頻寬,交換器廠商設計了鍊結聚合(Link Aggregation)的技術(圖十一)。
觀念上是將平行的鍊結視為同一鍊結,發送端將封包平均利用各平行鍊結發出,而收端則將各平行鍊結收到的封包聚集一處處理,不會由另一路繞回。在兩方都有此設定時,由擴張樹協定視之,可作為一埠,而非多埠,因而沒有衝突。橋接器標準規定同一會談的封包順序不可以改動,所以封包分配給平行鍊結時通常將目的位址及來源位址作運算來分配,使同一組的目的位址及來源位址必定走同一鍊結,解決順序的問題。
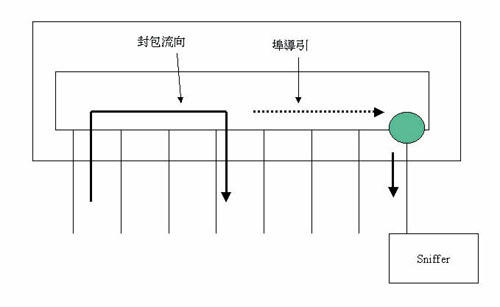
埠導引(Port Mirroring)
在傳統乙太網路中,由於屬廣播性質,每一節點均可收到全部的網路通訊狀況,任一節點只要將其乙太網路埠設定為全收(Promiscuous)狀態,即可收到所有網路封包,所以網路若發生問題,藉網路分析儀(Protocol Analyzer)或具此功能的軟體,就可以觀察所有的通訊而容易地發現問題所在。相對地,任何人均可監聽所有資訊,導致安全性不足。在集線器成為主流後,因而發展了防竊聽(Eavesdrop Prevention)功能來防堵此安全漏洞。
交換器則本身就有過濾本地封包的功能,封包只會送至其目的埠,而其他埠不會收到,安全性沒有問題,但管理上會有不便。若某埠發生問題時,除非將其線實際拆下,插入網路分析儀,否則無法觀察該線路的收送狀況。交換器特別設計此功能,可藉網路管理的設定,將某一埠收送的封包複製一份到一設定的埠上,而該埠可以接上網路分析儀加以分析(圖十二)。
第三層交換器(Layer 3 Switch)
第三層即網路層,網路層負責將各種不同的區域網路、都會網路、廣域網路等連接起來,成為一個大網路。目前風行全球的網際網路(Internet)就是最成功的例子。網路層提供一個統一的定址方式,使遠在天邊的兩個節點能互相取得聯繫,最重要的是訂出整個網路的路由(Routing)方式,使網路封包離開原節點後,經過一連串的路由器(Router)轉送,最後到達目的地。
如此看來,路由器與橋接器有許多相似之處,但這只是表面上的。橋接器的基本假設是封包可用廣播的方式送到目的地,因此若有未知方向時,就用溢流的方式解決,所以橋接器只是盡力做到過濾的功能,而沒有義務負責封包的去向。發送封包的節點不須知道橋接器的存在,而是假設目的節點就在身旁,橋接器則是擔任一個透明的角色,在幕後將封包送到目的節點。以定址而言,乙太網路位址無需考慮網路的結構,只須每個位址均能唯一即可。這種作法對較小規模的單一區域網路而言很方便,但絕對無法用來建構全球網路。以網際網路的龐大,如果允許盲目傳送,很快就會癱瘓,因此網路層的封包,必須是以主動的方式轉送,每一點都需要知到下一點的所在。
每一種網路層協定的設計各有不同,這裏僅舉IP協定為例。IP路由器的轉送方式是由收到的封包檢查其目的網路位址,查路由表(Routing Table)判定封包的輸出埠而將其送出。封包的目的位址如果無法查出應送的方向,則該封包被丟棄,並發出ICMP錯誤報告封包給原發送者。
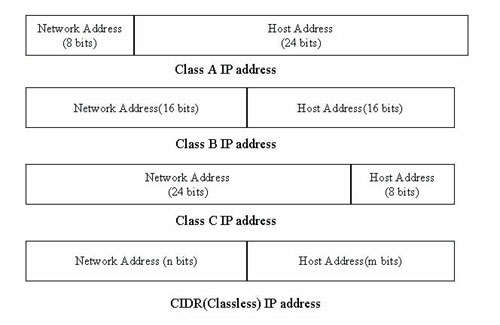
IP位址的分配也是轉送機制的一環(圖十三)。每一個IP位址分為兩個部份,前面一部份稱為網路位址(Network Address),代表網路的識別碼,後半部稱為節點位址(Host Address),代表節點本身。第四版IP協定(IPv4)的位址為32位元,網路位址與節點位址的位元數則不一定。過去的標準分為A,B,C等等級,代表不同大小的網路,但由於實際管理的需要,往往用子網路罩(Subnet Mask)來設定不同的位元分配,近來由於IP位址在網際網路的爆炸性發展下已不夠分配,乃採取新的CIDR標準,即允許任意分畫網路位址與節點位址的位元數,以將IP位址作更彈性的分配。
IP位址的分畫有甚麼重要呢?每一個路由器的埠連接的就是一個子網路,其中每一節點都擁有相同的網路位址,及不同的節點位址。子網路的位址就定義在埠上,一個封包進入一個路由器後,正常情況有兩種可能,一為目的位址的網路位址部份與某一埠的子網路位址符合,表示該封包已到達終點,應由該埠送出,到達目的節點;另一種情況是查路由表後,找到送到該目的所應利用的下一路由器與應送出的埠,將封包送至下一站。由於IP位址的位元數有限,所以子網路的節點數應有較實際的估計,使用較合理的位元數作網路位址。由以上可知,路由的方式與橋接有極大的不同。
由於路由器的硬體架構與橋接器十分類似,只是封包的解讀與轉送規則不同,所以其發展的途徑與橋接器十分相似。最初以一些硬體的設計來輔助主處理器,然後以特殊設計晶片來接管,也稱為交換器:第三層交換器(Layer 3 Switch),如第三層交換器僅提供IP協定,稱為IP交換器。
在廣域網路的產品中也有IP交換器,是非同步傳輸模式(Asynchronous Transfer Mode,ATM)交換機技術的IP交換器,雖然也同樣是路由器的加強版,但ATM技術與乙太網路有很大的不同,兩種交換器的設計及解決的問題不同,所以在此按下不表。第三層協定的封包處理,程序如下:
(1)解讀封包的資料鍊層,判定第三層協定的種類。乙太網路封包的位址欄位後,有一個型態欄(Type),通常是用來選擇第三層協定,例如0800h代表IP協定,8137h代表IPX協定,819Bh代表Appletalk協定等。判定協定後,再按照各協定的規則處理其訊頭。
(2)IP協定的轉送是看IP訊頭中的IP目的位址(Destination IP Address),根據其中的網路位址欄位來決定送出的埠。如前所述,網路位址欄的長度是不定的,所以處理上比乙太網路位址表更複雜。在路由表中每一個網路位址均記載其位元數,而由IP目的位址本身無法得知其中網路位址的位元數,必須與每一個位址表中的每一列比較,由於各列網路位址位元數不一,可能有不只一個通過比對,此時必須選擇位元數最多的一列,這種比對稱為最長字首比對(Longest Prefix Match)。由位址表比對出的列選出應轉出的埠。
(3)轉送的對象有兩種情形。目的子網路在某埠上時,應直接送至目的節點,否則目標是下一個路由器。無論如何,封包送出時仍必需通過第二層,即仍須在第二層的訊頭上填上下一站的乙太網路位址,方能到達。IP層在這種轉換時倚賴一種ARP(Address Resolution Protocol)協定。ARP協定根據IP目的位址,在區域網路上發出廣播的ARP訊息。擁有此IP位址的節點會發出回答訊息,將本身的乙太網路位址回報。ARP所得的IP與乙太網路位址的對應表會儲存備用,所以ARP訊息不必每次發出。
(4)IP協定訊頭有些欄位必須處理,以符合IP協定的規則,例如有一個生命時間(Time-To-Live;TTL)欄,是用來防止網路無限迴圈的,必須在封包經過時將其減1,而TTL為0者不得轉送,若非已到達目的者應予丟棄。另外,IP訊頭有檢核碼,由於訊頭已修改,必須重算。
在第三層的加速問題,最顯而易見的問題是最長字首比對(Longest Prefix Match)。由於位元數不定,一般的散列法(Hashing)無法使用,但順序比對及二元比對又不足用來處理每一個經過的封包。在路由器的設計上,這原就是一個核心問題,硬體加速技術要考慮硬體的可實作性,限制就更多了。
最長字首比對法目前已有多種方式可達成,有些也能用硬體實作。但總之比第二層位址處理的困難,也可能有些限制,例如需要大量記憶體,或資料結構複雜,不易修改更新等。
以內含定址記憶體(CAM)而言,一般的CAM也無法使用,而必須使用三元式(Ternary)的CAM,即每位元可有3個狀態,以便表示不定長的內容。由於網際網路的發展,及技術的相對難度,雖然目前這種CAM成本仍高,未來應用的可能性很大。目前一些號稱IPCAM的晶片,主要就是提供這種功能。
硬體成本較低的做法是避開硬體的最長字首比對,仍用軟體解決,但用硬體處理ARP對應表。這種作法雖然較全硬體處理無效率,但所差並不多。一個交談的第一個封包可能需要軟體處理,因為該IP目的位址並未出現在硬體ARP表中。在軟體處理後,新的IP位址填入表中,此後的各封包即可利用此ARP對應由硬體轉送,而不再透過軟體動作。這種一次路由、多次交換(Route Once, Switch Many)的作法實際的效能和其他方法是差不多的,又可以類似第二層的完整比對(Exact Match)法,用散列法等比較簡單的方式達成低成本設計。
路由表的建立可由事先規劃,或透過路由協定(Routing Protocol)彼此交換所知的訊息。由於網際網路的廣大,每一個節點能做的規畫很有限,主要還是要靠路由協定來維護網路上的路由資訊。IP路由協定有兩類,一種是在一個網域內部的,稱為內閘路協定(Interior Gateway Protocol,IGP),一種稱為外閘路協定(Exterior Gateway Protocol;EGP),是用來交換網域間的資訊的。IGP較常用的有RIP(Routing Information Protocol),及OSPF(Open Shortest Path First)等協定,而EGP則主要用BGP(Border Gateway Protocol)協定。路由協定是用來交換路由器間的資訊的,通常是用軟體來執行,而不可能用硬體加速。
第三層交換器有不少配合的功能,IP群播是其中重要的一個。IP群播的設計很早就很完備了,但實用上一直在實驗階段,原因是過去需求的誘因不大,過去的硬體能力也不足以支應IP群播的效能需求。目前情況改變了,由於多媒體應用的風潮,IP群播應用已達實用階段,而硬體技術的進步則使這種應用逐漸變成可行。前述有關乙太網路的群播功能,事實上主要還以IP群播的應用為主。
一般第三層交換器可能會同時提供其他協定的路由功能,例如IPX協定,Appletalk協定等,這些協定與IP協定的規則並不相同,所以必須針對各協定設計其路由功能及路由表的查對功能,使交換器的功能更加複雜,成本更高。是否提供這些功能,就是設計上的考量了。
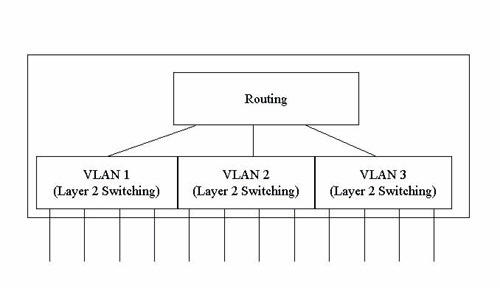
多層次交換器
一般路由器通常埠數不多,因為埠所連的就是分別的子網路,而一般企業並不需要設定許多子網路,通常僅照部門或樓層作大體的區劃。但目前交換器設計的埠數可以相當多,如果第三層交換器仍將每一埠設定分別的子網路,這種設計並不實用。比較可行的是將第二層和第三層功能一同考慮,規畫出多層次交換器。如(圖十四),第二層交換器利用虛擬網路區分子網路,每一個虛擬網路組規畫為一個子網路,第三層交換器則為虛擬網路間之路由器。當然,這是觀念上的表示,在實際的邏輯設計上可以一氣呵成。
多層次交換器的功用
以實用的角度來看,第二層交換器已經提供相當大的頻寬給每一個埠,為甚麼在乙太網路建構中規畫第三層的交換呢?換言之,為甚麼不將整個乙太網路規畫成一個子網路,免去第三層的麻煩呢?理由如下:
(1)第二層交換器無法克服的是廣播封包的問題。在橋接機制下,廣播封包必須無條件的送達每一節點,所以一個橋接器的網路稱為一個廣播域(Broadcast Domain)。在節點個數增多後,廣播封包的比率會增加,到達一個百分比後,網路的效率會受影響,而且廣播封包每一個節點都必須接收處理,如此會全面降低每一個系統的效能。減少廣播封包的方法是將網路分為多個子網路,因為廣播封包不會跨子網路傳送。
(2)系統管理者基於管理的方便,會希望將網路分為若干相隔離的子網路,以減少各群組的互相干擾,或機密訊息洩漏的機會。
第四層交換器
第三層交換器已解決網路層的路由問題,為何還有第四層及以上的交換器?第四層是傳輸層(Transport Layer),強調的是兩節點的應用程式間通訊管道的建立與使用,換言之,第四層功能已關切到個別的應用,而不只是節點間的通訊。原來在路由器的設計上,有一些方便管理的功能,例如過濾位址及應用的安全功能等、後來對服務品質(Quality of Service)的重視,開始加入有關頻寬管理的功能及RSVP協定等。這些附加或新加的功能,都強調對不同用戶及應用的辨認及差別處理等,所以在交換器加入這些功能,就稱為第四層交換器。第四層交換器所具備的功能有:
(1)第二、三層交換器的橋接與路由等功能。
(2)訊流分類功能(Flow Classification),即能觀察第二、三、四層訊頭,作適當的分類。分類的方式可能分為幾個等級(Class),或細分為微訊流(Microflow),即用三、四層訊頭中的五個欄位辨識封包所屬的會談(Session),賦與一個訊流編號(Flow ID),以作後續的處理依據。
(3)服務品質(Quality of Service)的管理:根據封包所屬的類別,給予一定的通訊品質,如頻寬、延遲等的保証。以微訊流的方式管理通訊品質,可以將每一個會談的通訊品質控制得相當準確,然而因為需要在過程中保留沿途的所有路由器的頻寬,在網際網路的上面運用的可行性不大,所以多只限於在小範圍內的應用。以分等級的方式處理服務品質的問題,稱為有區別服務(Differentiated Service),是目前在大網路上實施服務品質管理比較可能的方式,。
(4)流量管理:在一些特別的設計中,交換器可以主動運用TCP協定的流量控制(Flow Control)功能來控制各微訊流的流量,以調整流入交換器的封包率,而不待進入後才作處理。
(5)政策(Policy):根據不同的網路使用者及應用的需求,設定賦與的頻寬,或設定進入的管制,不允許某些使用者進入等。管理者設定的規則(Rule),轉換為實際交換器的操作行為。
第四層以上的網路功能,雖然有一些標準,但由於層面上相當廣泛,在產品提供的功能上個別化的傾向很大。號稱第四層以上的交換器目前在定位上仍趨向較高階的使用者,而不強調產品的普及化。
在第四層以上的產品設計,額外考慮的是每一個封包必須檢的欄位更深,需要額外的規則表(Rule Table)以為比對,而頻寬管理上要能追蹤許多的微訊流,管理其個別的頻寬使用量,在設計上也是很大的挑戰。在多層次交換晶片的設計上,多半會提供某些第四層的處理功能,但如何訂出實用的軟體功能,以達成設計的目的,是第四層產品的課題。
結論
交換器是目前乙太網路發展的主流方向,目前國內的努力,大多數仍在提供更具成本優勢,更高埠數的產品,以爭取更大的市場佔有率。這誠然是國內競爭優勢的展現,然而具備網路管理功能,以及第三層以上的交換功能的交換器,能夠提供更高的附加價值,若能成功打入企業市場,其發展更不可限量。站在產業昇級的觀點上,如何提昇產品的位階,增加競爭力,是企業求生存發展的不二法門。這也是高階交換器一直受到囑目的原因。要發展更高階的產品,除將系統晶片化(System-On-Chip)外,軟體的角色也是關鍵,這也是國內亟須加強的方向。