数据仓储的重要技术议题
如同其他系统一般,要导入数据仓储之前要非常了解用户的需求,但除此之外,使用数据仓储有两个非常重要的技术议题要考虑:「数据扩张」以及「数据转入」问题。「数据扩张」问题来自于数据由RDB(Relational Database)转为MDDB(Multi-Dimensional Database)过程会进行预储及预算,因此会耗用大量的空间储存数据;而「数据转入」问题则来自传统交易系统普遍有数据不一致、数据冲突状况,当有许多交易系统要同时转入一个数据仓储时,这个问题就会变得非常严重。
你能想象1Giga的RDB数据转为MDDB后变为100Giga的情况?如果RDB转为MDDB时,RDB本身就是「垃圾进、垃圾出」,所作出来的MDDB信息有用吗?这篇文章将为您探讨这些问题,并看看业界用何种解决方案处理。
当RDB变为MDDB时的数据扩张状况
这是一个非常严肃但又很少人会去注意的问题,如果你在业界真的要去进行数据仓储方案的开发,假设你有1Giga的RDB数据(在连锁零售业,一个月就会有超过一Giga的销售数据,或是500Mega的订购数据),有20个Dimension要分析,你绝对想象不到当数据变为MDDB时,由于经过预算与预储,可能会变成上百Giga甚至上千Giga的窘境,你的硬盘将会爆掉,你也会发现你买硬盘或其它储存装置的钱比起你买数据仓储软件的钱还要来得多!
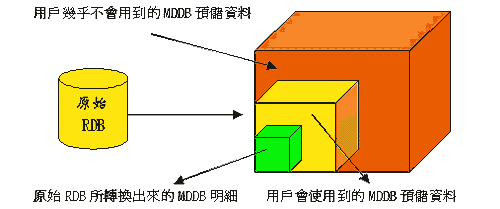
RDB数据变为MDDB数据时之所以会产生的大量数据扩张,主要是由于预储的关系。为了追求更好的处理绩效,一般OLAP软件都会利用预算与预储的方式,事先将用户可能查询的汇总结果进行运算并加以储存,因此数据仓储会比一般的数据库得大,如(图一)是一般数据仓储数据的组成,包括原始的RDB转为MDDB的原始明细数据、用户真正会用到的预储数据,以及为了那些天马行空、不可知的用户需求而产生的预储数据。原始的数据只占了MDDB很小的比例,可是随着分析维度变多,那些天马行空的数据所占的空间就会不断的变大。
这种数据扩张的状况是可以理解的,不过由于受到下列四个因素的影响,MDDB的数据扩张似乎在业界都还没有被优化的处理:
● 数据仓储软件对于稀疏数据的处理不当:假设你有二十笔销售数据,分别属于A、B、C、D、E、F、G、H、I、J等十种商品的销售类别数据,其中A、B、E、F、G、H类别是完全没有数据,当我们以商品与门市建立二维的MDDB时,在正常情况下A、B、E、F、G、F应该是不会与任何的门市产生汇总式数据的,可是,大部份的软件在进行前置性的预算与预储时,却是会为其保留空间,但这些空间事实上是没有数据的!当这种数据稀疏状况非常严重、而要分析的维度又很多时,这种空间浪费就会是一个很严重的问题
● 多维式数据储存策略未臻完善:在数据储存策略方面,一般可以分别依用户状况将数据储存在MOLAP(查询最快,但最耗空间)、ROLAP(查询最慢,但最省空间)或HOLAP(介于MOLAP与ROLAP之间),这三种策略都是一种直觉式的策略,也就是说以较多的储存空间换取较少的查询时间,或是以较少的储存的成本,但牺牲较多的查询时间。这些作法都不是最好的,在硬件速度不断进步情况下,应该可以利用更好的数学运算求取储存成本与查询时间的平衡点
● 软件缺乏数据压缩能力:有少数的软件提供数据压缩功能来降低储存空间的使用量,不过相对于用户查询时的时间耗费,用户并没有占到太大的便宜,这是一个治标不治本的方法,并没有真正解决数据仓储数据扩张问题
● 数据仓储软件本身的问题:软件本身也是会有Bug的!有时一个储存策略的选择错误或是算法有问题,就会让数据以等比级数式的成长,但由于你是用户而不是研发人员,这种错误通常是很难被发现的
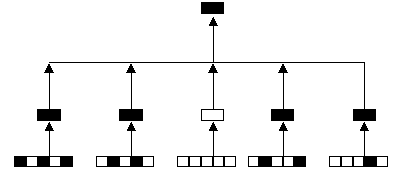
很明显的,似乎没有什么技术性方法可以降低数据的扩张,既然如此我们就来看会扩张到什么程度,以及数据稀疏对数据仓储的影响。(图二)是一个一维的OLAP分析个案,假设有25种商品销售类别(你可以把这25个类别的基本数据视为是OLTP当初要转入的数据),这些类别又分别属于5大群组,在正常情况下,系统会产生5大群组的汇总数据,及所有的商品的销售汇总,它将会使用31个空间(25+6),而数据的成长率则是1.24(31/25),如果把没有存放数据的类别拿掉,则只使用13个空间(5+8),而数据成长率则是1.625。
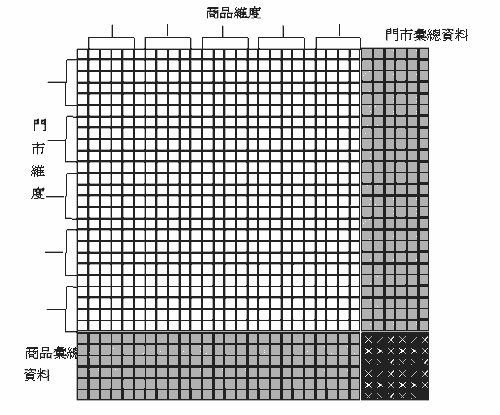
如果把图二变为二维呢?假设是有25种类别的商品与25种类别的门市(这些类别的门市又分为5大群组)要进行门市的二维交叉分析,会产生多少数据?在(图三)中充份的提供了答案。系统将会产生625(25x25)个基本的类别交叉分析数据空间,以及产生336个汇总式数据(27x27-625),数据的成长率将是(625+336)/625,也就是1.5376,如果把没有存放数据的类别拿掉,会出现什么情形?曾有人以计算机仿真做出下这样的研究:
从这里可以归纳出由RDB转为MDDB时数据膨胀的一些因素:
● 维度与阶层因素:假设RDB中只有一笔数据要转入MDDB,在一维中商品有一个维度,25个基本类别、3个阶层,总共使用了31个空间,可是多了一个门市维度,它也有25个基本类别、3个阶层,却使用了961个空间!比原先的一维状况多使用930个空间。这种空间膨胀的问题将因为维度与阶层的变多而大量扩张,并不会因为RDB数据的多寡而受影响;
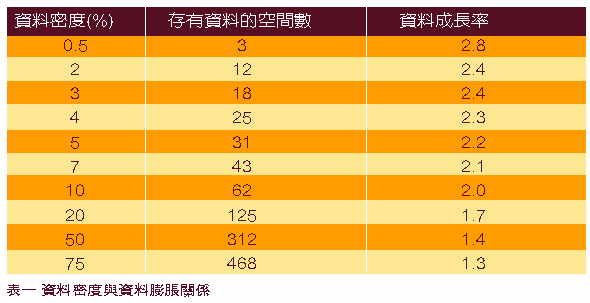
● 稀疏数据处理因素:从(表一)中可以很明显的看出来,MDDB是否有稀疏数据的处理能力,也将会大大的影响数据膨胀的程度;
● 数据储存的策略:是选择ROLAP、MOLAP或HOLAP储存数据仓储数据,以及RDB原始数据是否被转换并储存于MDDB也都是影响数据膨胀的因素;
● 预储的程度:是所有的各阶层、各维度都要进行预算与预储,或是某一个阶层以上才进行预储,例如依时间将数据分为周、月、季、年,选择计算到周与选择计算到年,所耗用的数据空间可能会有52倍的差距;
到目前为止,市面上的软件还没办法很有效的控制数据扩张的问题,反到是从目标导向方式,回过头来控制你可以使用的空间或是预储的程度,如Microsoft SQL Server 7.0,是利用对预算与预储程度,或是愿意使用多少空间储存数据,来控制数据空间的使用。
数据迁移问题
另一个在数据仓储运作中非常重要的问题是:数据的移转问题。在数据由RDB移到数据仓储的多维式数据库过程中必须注意到完整性与正确性,包括:
● 每日事务数据的移转:一般业界对数据仓储的应用很少会要求到数据具有实时性,大部份的情况只要做到每天晚上有批次可以将当日事务数据移转过去就可以,不过在移转的过程要注意时间控制,以零售业为例,晚上10点到次日凌晨3点通常是回收门市文本文件订货/销售数据及转换成数据库格式的时间,如果在这一段时间进行数据迁移必须考虑数据锁定、肮脏读取(Dirty Read)、网络数据流量过大的问题,而如果在凌晨3点以后才开始进行数据迁移则可能会有时间不够的困扰,再加上如果操作系统、交易系统每日有定时的备份、复制、镜射,那么可以用来移转的时间就会非常少,因此如何在有效时间内把数据迁移过去要非常仔细的计算。
● 移转的正确性:信息界的名言「垃圾进,垃圾出」,在数据迁移的过程更要注意。数据仓储的数据是由很多不同的交易系统所汇集而成,而每个交易系统本身就有一些一致性与完整性的问题,汇整成一个系统后这些问题同样会出现,而且可能更严重。这些问题包括︰
1. 一致性与完整性问题(每个事务数据库本身是否有数据冲突、数据重复、引用完整性的问题,以及这些交易系统汇集成一个多维式数据库时是否会有这些问题)。
2. 单位问题(同样是金额的字段,在A系统是以千元为单位,在B系统却是以元为单位,在转入过程一定要思考清楚应用何种单位,如用元是否会造成报表字段过长,如用千元则要考虑500元以上和以下应如何四舍五入)。
3. 同义词问题(ROC、R.O.C.、Republic OF China这三个都是同义字,但由于输入方式不同却变成三笔数据)。
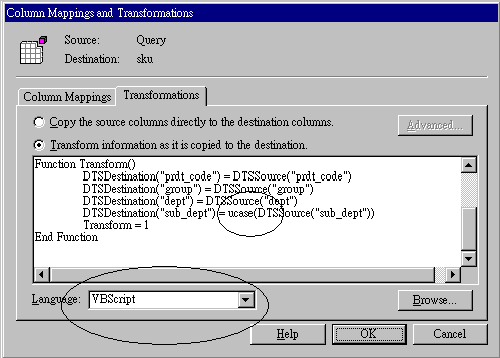
4. 技术问题(某些数据库对特定字符有排斥作用,如SQL Server的字符串内不可以有「 ‘ 」,当你输入「He's a student」会被SQL Server认为是一个错误,要解决这个问题必须要另外用一段处理程序处理)(图四)
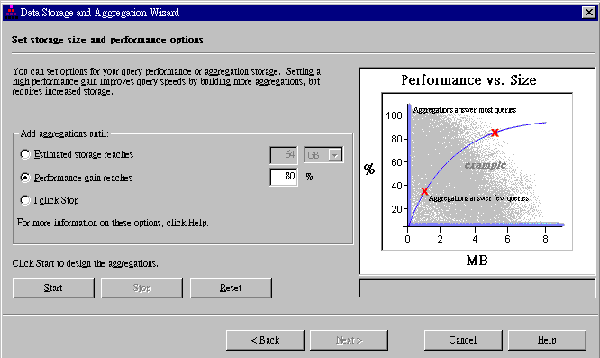
| 《图四 SQL Server 7.0利用Storage与Performance控制数据库的大小》 |
|
● 缺值的处理:只要有系统的地方大概就会碰到数据缺值的问题,可能是Null、空字符串或0,在数据迁移的过程必须对这些记录进行判别,依使用状况将该记录舍弃(但可能在计算笔数的时候少一笔)或保留(但在计算测量值总合的时候却可能会造成困扰)。
Microsoft SQL Server 7.0的Data Transformation Services是这一版SQL Server最重要的工具之一,可以在数据库移转过程对要移转的数据进行调整,包括数据内容的运算(大小写、字符串分解、加总)、数据过滤(只转入符合条件的数据)及数据组合(从不同表格中抓取数据字段再转到SQL Server的同一个表格),这个功能比传统Access的Import/Export、或Foxpro的Upsize有更强大的商业价值。(图五)
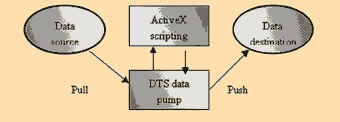
MS DTC基本上是经由OLE DB进行各种数据的转入和转出,而所有数据转换过程中的定义则是都储存于Microsoft Repository。它是利用拉与推(Pull and Push)的帮浦原理,从源数据库抓数据出来丢到数据帮浦(Data Pump),经由Microsoft ActiveX scripting function(Microsoft Visual Basic ,Scripting Edition、Jscript development software或PerlScript),进行数据复制、验证和转换,然后再传给目的数据库,目的数据库可以是经由OLE DB或ODBC连接的数据库,也可以是ASCII或HTML。这整个转换的过程的历史纪录和每一个数据处理方式的定义都会被记录下来,以让用户知道数据从何而来与将往何去,也可以做为开发人员稽核的依据。(图六)
结论
由于有SQL Server之类的数据仓储解决方案出现,使得中小企业有机会用极少的投资就享有以往大企业才能使用的信息科技优势,中小企业可以经由数据仓储工具去分析各种信息及发现未来趋势。不过就如同导入其它系统一般,都会有一些风险存在的,数据仓储观念的导入除了要注意是否符合用户需求外,还要注意数据膨胀及数据迁移问题,本文以SQL Server 7.0为例提供一些看法让读者了解这些问题的处里方式,以做为未来导入数据仓储的时的参考指引。
(网际先锋2000.1月号68期)