隨著電腦硬體及網路連線設備快速成長,網路上資訊量爆炸性的成長速度遠超過硬體設備的進步。如何快速有效地收集所須資訊,並且加以組織整理,已經成為現代人不可或缺的能力。本文將帶您一探搜尋引擎的基本運作原理,並經由分散式計算的架構來展望未來資訊搜尋的趨勢。
搜尋引擎的前身
在網際網路(Internet)尚未建立的年代,圖書館早已成為人類知識與智慧累積的重要地點。除了平面媒體如:報紙、書籍、雜誌、期刊等之外,想要在各種非數位媒體上搜尋資訊,不僅費時,而且並不容易找到所須的資料。
在1990年初Internet草創時期,World Wide Web(WWW,簡稱Web)尚未成型的年代,檔案傳輸主要是透過 FTP(File Transfer Protocol)的方式來進行。如果想要分享檔案,必須自行架設FTP伺服器,然後以口耳相傳方式告知親朋好友,該連線到哪個伺服器的哪個目錄才能抓到什麼檔案。後來大量匿名式(Anonymous) FTP伺服器逐漸架設起來,使得所有使用者都可以任意儲存或抓取各種檔案,其中被用來搜尋這些檔案的重要工具,就是Archie[1],這便是搜尋引擎(search engine)最早的起源。當時除了檔案之外,還有儲存在Gopher伺服器上的文件(只有純文字,不含圖片、聲音、影像等多媒體)可供瀏覽,而Veronica[2]便是其中用來搜尋Gopher文件的一個系統。
資訊超載(Information Overload)
隨著網際網路的蓬勃發展,Web已經逐漸整合各種數位媒體。在任何時刻,全球各地的使用者不斷以網頁(Web pages)的形式整理出自己所知的資訊,使得Web成為全球最豐富的動態知識庫。
自從2000年以來,Peer-to-Peer(P2P,對等式)網路架構逐漸引起廣泛重視。從Napster以MP3壓縮格式進行音樂檔案分享(file sharing)開始,到Gnutella、Morpheus,甚至是國內的ezPeer、Kuro等,各種檔案分享軟體充斥。這些P2P軟體將網路上所有願意分享出來的硬碟空間,整合成一個超大的網路硬碟,內容除了網頁外,還包含了其他媒體格式,如:文字、圖片、聲音、影像、...等,更加豐富了網路上的資源。
然而這些大量資料(data)如果不加以整理、消化,充其量只是一堆沒有用的垃圾。因此如何在龐大且不斷進化的網路資源中找到所想要的資訊(information),進而獲得知識(knowledge)、甚至智慧(wisdom),已經成為非常重要的課題[8],如圖一。
網路最佳工具 - 搜尋引擎
在這種資訊超載(information overload)的情形下,網頁搜尋引擎(Web search engine,或簡稱搜尋引擎)應運而生。早期的搜尋引擎,如:Yahoo,是採用人工方式收集網頁、整理資訊。他們以人工方式將全球的網頁分為數類,每一類再細分更多的子類(sub-category),形成一個階層式目錄(hierarchical directory),以供查詢。所有收集來的網頁,則依照內容性質不同分別放在不同類別底下。
人工分類整理雖然比較精確,但是效率相當差,況且Web data 瞬息萬變,Yahoo Directory無法即時反應出網頁結構的動態變化,便可能產生許多過時、無法連結的 dead link,也容易造成收錄網頁涵蓋範圍(coverage)有限的缺點。
因此,Lycos、Alta Vista等搜尋引擎開始運用電腦自動上網收集網頁,並加以整理以供查詢。之後,又有許多搜尋引擎紛紛以先進的技術,將搜尋結果由量的提升進一步邁向質的追求,從此搜尋引擎進入一個新的紀元。
搜尋引擎如何運作?
如圖二所示,搜尋引擎大致可分為兩個部分:一個是Web Crawler(或robot, spider),另一個是檢索界面(Query Interface)。通常大部分搜尋引擎是利用Crawler程式,將Web上的網頁,儘可能的抓下來 (crawling),並快取(cache)在伺服器上。然後根據網頁內容所出現的重要關鍵詞(keyword)建立一個索引 (index),以便日後能快速搜尋到使用者所想要的資料。當使用者透過檢索界面發出一個檢索(query)時,搜尋引擎便能查詢到檢索字詞(query term)相關的網頁,並將結果傳回給使用者。
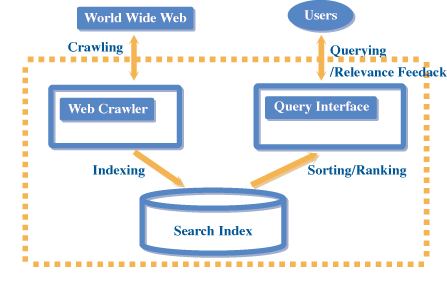
| 《圖二 Search Engine 的架構示意圖》 |
|
查詢結果
通常檢索越短、越模糊,找到的結果會比較多,但是可能其中包含不少雜訊(noise),並非我們所要的資訊;相反地檢索越明確,找到的結果會比較少,也比較精準,但有些時候涵蓋範圍(coverage)可能不足,無法提供足夠相關資訊。因此如何縮短使用者和搜尋引擎間語意上的隔閡(semantic gap),成了改善搜尋品質一個很重要的關鍵。
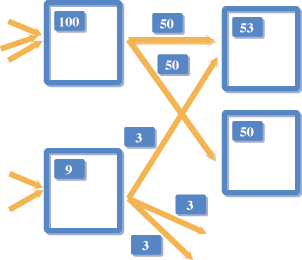
如果符合檢索條件的結果數量太多,使用者可能很難從中找出想要的,為了能更快速方便地挑出重要資料,通常會將結果依照重要性順序(relevance ranking)排序(sorting)。例如在Google中使用的是 PageRank[4]技術,利用網頁中鏈結結構的分析(link structure analysis),可以決定出各網頁的重要性分數,如圖三。
基本想法很簡單,一個網頁如果被連結(link)越多次,表示該網頁較重要(authoritative);而一個網頁的重要性又會隨著裡面包含的連結傳播(propagate)出去。套用這樣的遞迴(recursive)關係不斷計算下去,便可以算出每個網頁的重要性分數。事實上除了PageRank之外,其他人也提過類似的鏈結分析方法,例如Kleinberg的Hub-Authority[5]觀念,目的都是為了增進搜尋結果的品質。
常見的搜尋引擎
除了Google之外,目前常見的搜尋引擎有:Yahoo、Lycos、Alta Vista、Northern Light 等。每一個搜尋引擎所收集的網頁不同,索引方式也不同,因此同樣的檢索傳回的網頁及順序也不盡相同。通常依照搜尋的目的不同,我們會建議使用不同的搜尋引擎[6]。
另外,由於個別搜尋引擎的差異,使用者可能想要結合不同搜尋引擎的特性,彌補涵蓋率不足或品質不佳的狀況,以更快找到更多符合需求的資料。因此,有所謂的meta-search。也就是將一個檢索分別向數個搜尋引擎查詢,然後將各個結果分別列出或做某種結合。常見的meta search engine有很多,例如:Ixquick、Excite、Dogpile ... 等。
從集中式到分散式搜尋
搜尋所包含的抓取(crawling)、索引(indexing)、排序(sorting)等動作相當費時,而且須定期執行。如果單靠一個集中式搜尋引擎,要同時服務全球大量的檢索,不但效率差,而且擴充性(scalability)也不好,同時能服務的用戶端數量很有限。
因此想要增進搜尋效率,必須將負擔(load)分散出去。例如在全球各地設置備份伺服器(replica server),並且將各地的檢索依照其所在區域,分別重導(redirect)至相對應區域的伺服器,則服務效率會比較好,但是擴充性恐怕還是一大問題,因為如何佈署(deploy)眾多的電腦在全球各地,對於主機控管、維護、以及安全性都是極大的挑戰。
分散式搜尋與P2P
於是分散式搜尋(distributed search)的主要想法是將crawling、indexing及sorting等動作分散(distribute)到各個自願參與的(volunteer)主機上執行,如此,負擔不會集中在一個伺服器上,而是平均分攤到各個主機上,搜尋效率可再提升。同時藉由分散式計算擴充性佳的特性,使得搜尋工作變得更穩定(robust)。
最近三年來除了Web 之外,P2P網路成了另一個熱門的儲存媒體。一般而言,P2P網路依其架構可分為集中式(centralized)、純P2P與混合式(hybrid) P2P網路。例如 Napster採用的是集中式架構,所有的使用者及檔案傳輸都要經由集中的伺服器來管理。而Gnutella則是純粹P2P,也就是說所有主機地位完全均等,沒有任何一台主伺服器。Morpheus則是介於兩者的混合式架構,即每個區域有super-peer,集中負責該區域主機的管理;但是super-peer之間則仍是純粹P2P。
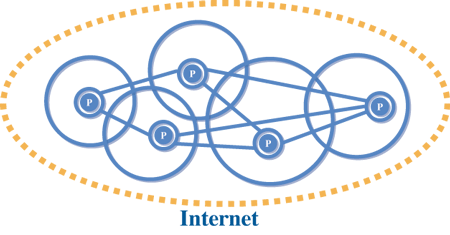
P2P網路架構主要的好處是開放(open)、擴充性(scalability)、匿名(anonymous)與容錯(fault tolerance)。開放式架構有助於資料的分享,擴充性可以同時服務很多人,不致影響系統效能,匿名可確保使用者身份的隱私,而容錯則可讓任何人隨時加入或離開P2P網路,不會對整體產生太大的影響。請參考圖四。
一般在集中式P2P網路中,比較容易搜尋,因為每個peer都要登入伺服器,因此與傳統Web搜尋沒有太大差異。所以,目前常見的分散式搜尋引擎大多為Gnutella-based純粹P2P的架構,例如 InfraSearch、Grub、...等。
另外,一般P2P client也大多含有搜尋檔名的基本功能,因為純P2P網路並無法確認每個peer儲存有哪些檔案,必須依賴搜尋功能。但由於目前儲存在P2P網路的檔案並沒有一個很好的方法來確認其真實性(authenticity),只能根據檔名(filename)來做索引。至於一個檔案是否為合法授權(authority),或是內容與檔名是否名符其實,目前只能靠投票(voting)這類的機制讓使用者來評分。如果能在分享檔案時加入簽章(signature),而使用者能在取得檔案時做驗證(authentication)的動作,或許更能夠確保P2P檔案的合法性與內容的正確性。
另外,各地主機通常會存有當地常被查詢的資料。基於這種區域性(locality)的特性,透過各地主機的合作,有機會找出更多的資料。由於傳統搜尋引擎僅止於網頁的搜尋,因此如果能將搜尋範圍擴展到P2P網路上所分享的檔案,其資料涵蓋的範圍更廣,所能收集到的人類知識也能更廣。
但是,這種作法有個缺點,因為純P2P廣播(broadcasting)的關係,每個 peer地位相當,同時是client也是 server。因此所有檢索都有可能流經許多peer才到達使用者,效率有待考驗。一般解決方法是採用cache來增進效率,同時又可增進區域性檔案存取效率。
如前言所述,資料(data)並不是知識(knowledge),它必須經由整理成為資訊(information),再經由適當的理解才可能成為知識(knowledge),因此越大量的資料就須要更快更好的處理。此外網路上資料的品質有待驗證,尤其是P2P網路上的資料,如果連最基本的資料真實性(authenticity)都無法確認,就更不用提要在其中擷取出什麼有用的資訊(information)了,因為根本不知道裡面包含的內容是什麼。
展望未來
未來的搜尋引擎會是什麼樣子呢?應該要能做到:速度快(fast)、夠聰明(smart)、符合每個人的需求(personalized),而且要好看、易用(user-friendly)。
首先,速度是使用者對搜尋引擎最直接的感覺。除了資訊擷取(information retrieval)技術不斷再提升之外,P2P網路也許是另一個有待突破的領域。其次,由於每個人興趣不同,資訊需求也不同,因此搜尋引擎必須要能根據每個人的使用習慣加以學習、調整(adapt),才能更貼近使用者的需求。另外,使用者界面更是使用者直接面對的部分,如何在人機介面上做到易用(user-friendly),是必備的條件。
最後,電腦夠聰明,才能理解人們所須要的是什麼,這是所有電腦系統都想達成的目標。通常使用者很難用搜尋引擎查詢到想要的資料,大多是因為不知道如何發出比較精確的關鍵詞給搜尋引擎。因此未來的搜尋引擎要能夠幫助使用者清楚地發出一個查詢概念(concept),並且列出相關概念及資訊,並導引使用者點選,逐步修正找出想要的精確查詢。當然要達到這目標,還須要整合許多資訊擷取(information retrieval)及自然語言處理(NLP)中語法(syntax)與語意(semantic)的相關技術。
事實上,網頁探勘(Web Mining)已經成為目前學術研究中最重要的課題之一。因為Web所蘊藏的無數資源還在不斷成長,如果再加上P2P網路所能提供的資料更是驚人。因此,逐漸地搜尋將不再只是關鍵詞比對或是全文檢索而已。更重要的是,如何從這些資料擷取出有用的資訊。許多人類認為理所當然的概念(concept),在電腦中卻是困難重重。資訊抽取(Information Extraction)只不過是網頁探勘的第一步。抽取出的資訊還須要透過某種程度的理解(reasoning)的過程,才有可能進一步自動整理出像人事時地物等meta-data,然後才能談到真正的知識,這些都還有待進一步研究探討。
(作者為中研院資訊科學所博士後研究員:jhwang@iis.sinica.edu.tw)
表一 本文相關組織與網站連結



![《圖一 從資料、資訊、知識到智慧 [3]》](/art/2003/11/261648157673/p1.gif)