近年来网际网路的风行,带动整个通讯网路工业的发展,国内所擅长的制造技术,使不少通讯网路厂商在国际市场上占有一席之地。在整个网路通讯业中,国内较擅长的领域,仍是属于较偏用户端的网路卡、数据机等,及区域网路的设备如集线器、交换器等。乙太网路已是目前区域网路的主流技术,而交换器由于提供成倍的网路频宽,在ASIC技术不断突破下,成为技术开发的重点。因成本不断降低,可望成为将来建构网路的唯一基础设备。目前国内已有多家厂商投入交换器晶片、系统的设计,功能上朝向高频宽、多层次、高功能发展。本文尝试由乙太网路的技术发展轨迹,介绍交换器的由来及所谓多层次的观念与各种相关功能的关系,希望能使读者对交换器有较完整的了解。
资料通讯的标准,根据国际标准组织(ISO)所制定的开放系统互连模型(Open Systems Interconnect,OSI),包含七个层次,即实体层(Physical Layer)、资料链层(Data-Link Layer) 、网路层(Network Layer)、传输层(Transport Layer)、会谈层(Session Layer)、展示层(Presentation Layer)、应用层(Application Layer)。其中愈低层者与网路设备的关联性愈大,较高层者则与用户端的软体功能有关。一般资料通讯设备大多处理下三层,即实体层、资料链层及网路层,就乙太网路而言,实体层的设备为集线器(Hub),资料链层的设备为桥接器(Bridge ),或第二层交换器(Layer 2 Switch),而网路层的设备为路由器(Router),或第三层交换器(Layer 3 Switch)。高附加价值的网路设备则尝试监控更多层次的资讯,号称第四层,或更高层的设备。
乙太网路简介
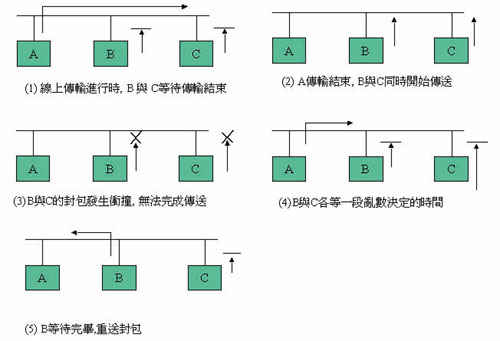
乙太网路是广播型态的区域网路,最初的型态是将各节点用收发器(Transceiver)接在一条同轴电缆上,各点之收送顺序则以一套公平竞争的协定决定,所谓CSMA/CD(Carrier Sense Multiple Access with Collision Detection),其方式为同一缆线由多点共用,欲传送资料时各自侦测缆线上是否已有资料传送中,而若无载波或待载波停止后即开始传送,此即载波侦测功能,但其时假若有其他节点也要传送,就发生碰撞而导致资料损毁而失败,此时碰撞检测即发现此状况,准备将资料封包重送,但先等一段由乱数决定的时间再送,以避免与同一对象再次碰撞。CDMA/CD为一种极简单的机制(图一),可使数以百计的节点在一个网路上收送资料,而不需任何特定的网路管理站协调管理。此机制与主要竞争对手权仗环网路(Token Ring)相比,在在显示其低成本及易使用的特性,从而终于席卷区域网路的市场,成为优势的技术。
乙太网路既为多点广播的网路,在资料封包送出时必须能含有位址资讯,以指定接收对象(图二)。封包发出后所有同一电缆上的所有节点都会收到,而每点的电路会将此目的位址与本身位址比对,仅有发送对象会将封包收下,而其他节点会将其丢弃。乙太网路的位址为6个位元组。在讯头中前6位元组为目的位址(Destination Address),即传送对象的位址,次6位元组为来源位址(Source Address),即发送点的位址。此位址是由设备厂商设定,每一连接埠需保证其为唯一,以避免重复而造成冲突,而发放位址的单位为制定乙太网路标准的电子电机工程师协会(IEEE),乙太网路的标准编号为IEEE 802.3。
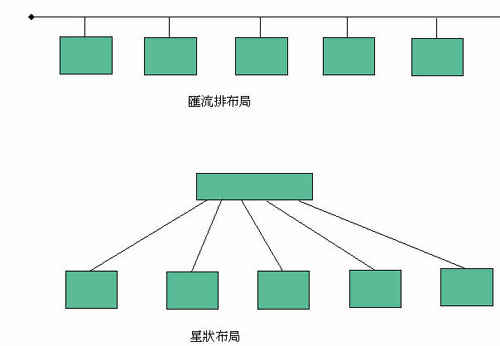
乙太网路的发展经过几次重大变革,首先双绞线(Twisted Pair)10BASE-T技术的发展,改变了网路布线的型态。双绞线技术必须利用主动设备-集线器(Hub),而不是单纯的电缆,而且电缆以点对点一一布设,而非串接,表面上都增加成本,然而点对点以集线器为核心的星状布局(图三),可平行于电话线布设,由墙壁插座引出,在大楼中较串接的同轴电缆方便,而且集线器可提供网路管理功能,使双绞线成为此后乙太网路的主流。在双绞线架构中,碰撞的机制是由集线器提供的,所以CSMA/CD的特性仍然维持。
乙太网路的速率也有惊人的成长。在乙太网路初期有1Mbps及10Mbps。其后10Mbps成为标准数年,接着100Mbps的技术出现,速率以10倍成长,不久后1Gbps(1000Mbps)标准完成,目前已在讨论10Gbps,而也有人已在提议100Gbps。
另一个变化是桥接器(Bridge)的出现。最初的乙太网路由同轴电缆及增益器(Repeater)构成,由于电波传导的速率及CSMA/CD时序的限制,网路的范围局限于2500公尺内。而网路节点数受CSMA/CD竞争机制的影响,不可能太多,否则随机碰撞将耗损所有的频宽,瘫痪整个网路。最初乙太网路标准估计,节点的上限是1024。
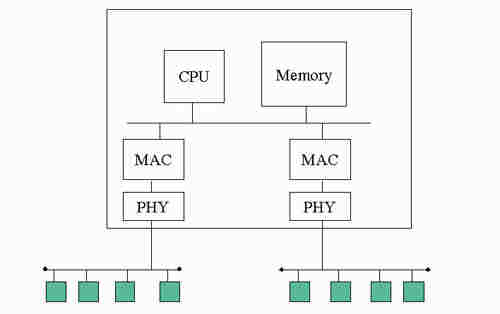
桥接器的发明解决了这些问题。最简单的桥接器构想如(图四)所示,是一个双埠的主动设备,中心为一微处理器,由于乙太网路的广播性质,所有缆线上传递的封包都可以由一埠接收,而由处理器在另一端送出。如此形成一个第二层(Layer 2)的增益器。由于封包由另一端送出相当于一个节点重新在电缆上发送,网路的范围可扩大一倍。经由多个桥接器,网路可以扩展到相当大的范围。然而桥接器本身的处理,及封包的收发免不了造成一些延迟,累积后对上层协定的运作会有影响,所以扩展的范围也会有限制。标准的建议是网路的直径不超过6个桥接器。桥接器的观念在每一个区域网路标准都有,所以是由IEEE的另一工作组所规定,标准编号为IEEE 802.1D。
解决节点数的问题则较复杂。为维持乙太网路的简单特性,桥接器的构想是透通的(Transparent),意即可做到即插即用(Plug-and-Play),而不须任何设定的动作。观察桥接器两端的资料流,可发现相当比例的本地化倾向,即传送来源及对象都属于同一端。假如能对这些封包作出判断,不将其转送,就可以大幅降低不必要的交通量而有效提升两端能支应的节点数。然而达成此点的技术相当复杂,也是日后交换器设计的关键所在。
判断封包的目的位址的节点位置,首先必须建立一个位址表来查询。由于必须具备透通性,此位址表不能要求用户来设定,而须由网路的运行得来。所以方法是在转送封包时将来源位址记下,填于位址表中,等下次同一位址出现于封包目的位址栏时便可作正确的判断。于是标准的乙太网路桥接器具有以下功能:
- (1)学习(Learning):将封包内的来源位址及封包的输入埠存于位址表中。
- (2)过滤(Filtering):将封包内的目的位址与现有位址表比对,若发现已存在,且其输入埠与新封包的输入埠相同,证明该目的位址与来源位址所属的节点都存在桥接器的同埠位置,无须加以处理,于是将该封包丢弃。
- (3)转送(Forwarding):若目的位址的节点位于另一埠的位置,则应将封包由该埠送出。
- (4)溢流(Flooding):若目的位址不存在位址表中,则该位址可能错误,或太久未使用,或新开机尚未传送过,无论如何,为达成透通性,应将封包向来源埠以外的所有埠送出,若该节点真正存在,即可收到该封包。
- (5)老化(Aging):桥接器是永续开机的网路设备,位址表经由不断学习,会逐渐增长,其中若有错误、更换、经常关机、偶而使用的外来节点等占据位址表,会将位址表填满,妨碍新的节点位址的学习动作,所以位址表内的有效位址均设定一定的时效,除非不断被使用而重设时限,否则时限到就会移除。
此一连串的处理程序有两种动作是关键:
- (1)封包的接收及传送:须将资料依序存入记忆体内,再依序读出。资料的量决定记忆体的频宽需求,及搬运资料的处理能力需求。随乙太网路频宽的不断上升,及桥接器埠数的增加,这种需求有增无减。
- (2)查表的效率:查表是基本的演算法之一,查表所需时间与所用演算法及表的大小有关。一般而言,桥接器的位址表是以千计的,而在此大小下,不同的演算法会有很大的差别。如按顺序搜寻(Sequential Search),其所需时间为O(n),即与表的大小成正比例,好一点的如二元搜寻法(Binary Search) ,所需时间为O(log n),即与表大小的对数成比例。如以散列法(Hashing),则所需时间约为常数,与表的大小无关。
处理封包时间的原则是,一个封包所需的动作必须在下一个封包完全接收到以前完成,否则以后的封包会丢失。乙太网路封包的长度规定最短为64位元组,而封包之,以10Mbps而言,一个封包允许的处理时间有67.2us(67.2x10-6sec),100Mbps则仅有6.72us(6.72x10- 6sec)。至于在1Gbps下,仅有672ps(672x10-9sec)。即便是10Mbps下,普通的微处理器系统利用最好的演算法也无法同时应付许多埠的封包处理需求。
微处理器是一种为一般运算所设计的电路,即使是简化的RISC处理器也有极复杂的结构,应付如此大量的重复处理工作并非所长,而多埠桥接器的处理需求已非单一微处理器的系统所能负荷。稍作简单计算即可了解:假如微处理器的时脉为100MHz,每一脉冲处理一个指令,则约略一个指令执行时有一个100Mbps埠的位元被接收。一个最短封包(64位元组=512位元)连前导讯号(Preamble)64位元及必需的封包间距(Interframe Gap)96位元,共672位元,即672指令内需处理完成,而两埠则每封包仅有336指令,更多埠则再递减。对微处理器系统运作稍有了解者都知道,接收及处理封包都需要很多指令的动作,系统软体及中断机制等有许多效率耗损,一个微处理器绝对处理不了几个埠,更何况桥接器又有许多网路管理功能,也需要一定的处理效能。
以特殊的硬体线路辅助处理大量封包,是很自然的发展。首先,利用直接记忆体存取(DMA)线路代替微处理器指令搬封包资料是最直接的方法。查表的动作可用内含定址记忆体(Content Addressable Memory;CAM)一种特殊的记忆体,可输入内容反查其位址)来处理。 CAM至今仍为高级网路设备常用的的线路,但由于成本高,一般的设计多不采用。
利用特殊设计的硬体线路来设计多埠桥接器(Multiport Bridge)的构想就逐渐成形。这种设备就被称为乙太网路交换器(Ethernet Switch)。名为交换器的原因是引用电信交换机的联想,而与微处理器系统的桥接器区隔。或问为何不用大量微处理器来克服效能障碍呢?答案是可以,但微处理器仍要特殊设计,这就是目前热烈讨论的网路处理器(Network Processor),原因是微处理器成本高,又需记忆体储存程式及资料,以及一些周边电路,不仅不经济,且设计上也困难重重。即使是网路处理器也必须克服成本的问题。
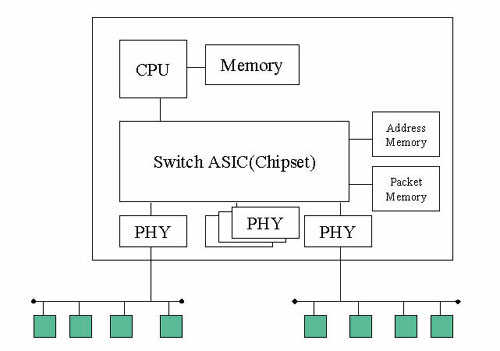
乙太网路交换器的系统架构如(图五)所示,由一组特殊设计的交换器晶片为核心,交换器晶片须利用两种记忆体,一种储存封包内容,一种储存位址表。提供网路管里功能的交换器仍有微处理器,但仅用于提供网路管理功能,封包处理由交换器晶片负责。
交换器晶片处理封包完全根据原有的桥接器原理执行,动作极复杂,而晶片内也包含标准的乙太网路媒介接取层(MAC Layer)电路,所以设计上并不容易。
最初交换器设计有所谓直通(Cut-through)模式,即封包接收一部份后即开始发送至另一埠,通常是目的位址查表完成,知道输出埠后,这种方式可以降低延迟时间。近期则不再强调,而都采取先存后送(Store and Forward)模式。原因是现在的交换器各埠的速率可能不同,可为10Mbps,100Mbps,或1Gbps,不同的速率不能用直通法。而且封包内容若到最后检核有误,本应直接丢弃,但前段内容已送出,无法挽回,不但增高网路错误率,连送出埠是否正确都无法确定,所以直通法已不再采用。
交换器的位址处理多采取散列法(Hashing),有些也利用CAM。与微处理器系统不同是散列法无法避免冲撞,即不同乙太网路位址对应到同一阵列指标(Index),竞争同一储存位置。微处理器程式的处理法是将冲撞的个体用指标(Pointer)连成一串,以后沿指标依序比对。但交换机晶片硬体设计不可能如此细腻,而且交换器设计以一定时限完成为原则,不可能沿指标无限搜寻下去。折衷的办法是设计数层阵列,即能包含如数的冲撞机会。万一发生冲撞的个体超过层数,则可牺牲较不常用的一个。
由于不存在或被剔除的位址是以溢流(Flooding)处理,不会影响使用者。最坏的情况是冲撞的各位址都不断出现,溢流不断发生,相当于有大量的广播(Broadcast)封包,使整个网路的效能大幅降低。所以散列函数(Hash Function)的选择十分重要,须在任何常见的情境中均能有完全散乱的分布。交换器晶片的散列函数设计如太简单,往往在标准测试组合下就发生溢流,造成效能数据偏低,虽然在真实环境不见得会发生,但对产品而言是十分不利的。
利用散列法的另一个缺点是保留的阵列大小无法充份利用,而且在使用的空间逐渐增加时溢流的机率会逐渐增加,到近填满时几乎每一个新位址都会冲撞,而且无法预测何时会发生溢流,除非网路管理者知道交换器的散列函数,又知道每一个乙太网路位址,预先加以防范,但这是不可能的要求。要减低这种效应的方法是尽量加大位址表空间,使其远大于一般网路的需要。采用CAM可充份运用每一个位址表空间,而且在完全填满前不会溢流。目前由于成本因素仅在高阶的产品见到,未来若ASIC技术进展到能使交换器晶片能直接包含够大的CAM部件,则使用CAM会是一个较理想的方式。
交换器晶片能支应的埠数也是一个重点。交换器的设计有两种主要方式,一为共享记忆体(Shared Memory),另一种为纵横交换器(Crossbar Switch)。共享记忆体为传统微处理器系统架构的类型,只是用硬体电路处理封包,能支应的埠数由硬体的效能决定。一般而言,逻辑电路较容易设计支应高频宽,所以频宽的要求在记忆体上。每一个封包需两次处理,一次因接收而存入,另一次因发送而读出,所以100Mbps的埠需要200Mbps频宽。8埠交换器需要1.6Gbps频宽,24埠需要4.8Gbps,1个1Gbps埠需要2Gbps,依此类推。由一组交换器晶片的埠数可直接推出其封包记忆体的设计需求。由于记忆体能支应的频宽是固定的,高频宽可加宽记忆体的位元宽度来设计,如用128位元宽度可处理32位元宽度的4倍频宽。位址记忆体的频宽要求视位址表的结构而定,大体而言,其设计约与封包记忆体同等级。
如果记忆体的频宽低于埠数的需要,则该交换器晶片的设计无法达成线上速度(Wire Speed),即无法让所有的埠用全速运作。这种设计在低成本的情况下可能被接受,因为一般网路不可能随时所有埠以全速运作。以往传统的两埠桥接器无法达成线上速度的也所在多有。若频宽需求在运作时被超越,可能的处理方式为:
- (1)丢弃新接收的封包,由上层协定自行重送。
- (2)以流量控制(Flow Control)法降低输入速度。
由于个别埠的输出频宽在一般情况下也可能发生超载的现象,例如许多埠同时向单一埠转送,所以流量控制及丢弃法都是交换器应处理的情况。
共享记忆体的设计有其瓶颈,频宽不可能无限加大,记忆体加大位元宽及提升频率,都会增加成本及设计难度,所以需要找到更经济的方式来提高埠数。
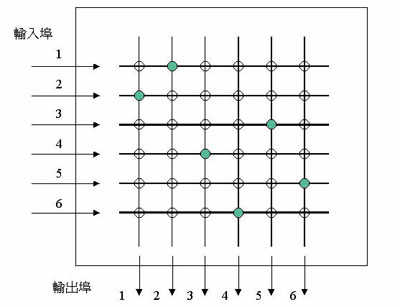
(图六)显示一个纵横交换器的设计。各埠或各组共享记忆体的埠独立处理其封包,中心为一纵横交换器。纵横交换器的设计最简单是由多工器(Multiplexer)组成的交换阵列,藉由控制讯号打开阵列的交叉点接通线路,如果不同的输入埠同时希望接通不同的输出埠时就可以有效运用所有的频宽。这种设计十分类似电信交换机的线路交换(Circuit Switch)技术。由于纵横交换器的设计可以用较低的成本达成很高的效能,所以是交换器设计中常用的技术。
或问为何不都用纵横交换器?封包记忆体及位址记忆体都是很高的成本负担,在经济可行的设计范围内让更多埠共享是较有利的。纵横交换器还有其特殊的瓶颈问题,即列头阻塞(Head-of-Line Blocking),由于其下层晶片都必须将封包排队以通过交换器,若第一个封包的出路阻塞,就会妨碍其后向其他未阻塞出路的封包的通行,所以运用纵横交换器是一种设计上的取舍。高埠数交换器的设计往往是这两种设计的混合,如以共享记忆体能以较经济方式达成的最高埠数为基础晶片,再用纵横交换器层叠以提高埠数。
另一种设计是环路设计,其原理有如权杖环网路(Token Ring),如图所示。其核心为一高速的环状骨干,封包循环运行后到达目的晶片后送出。环路的设计很有弹性,如各晶片的频宽总和小于骨干速率时系统可达线上速度,若将更多交换晶片组成环,可设计出超载的系统。但环路设计的封包须循环路前进,可能有较多瓶颈。
乙太网路的发展历史为解决网路的种种问题,发展出各种特殊的功能,以下将较重要的列出,以为交换器设计的参考:
全双工(Full-Duplex)
乙太网路最初的CSMA/CD法则,是半双工的(Half-Duplex),即送与收不能同时进行,这是因为多点(Multipoint)网路本来同时只能有一家发送。在交换器成为主流后,全双工的方式成为可能,而标准也迅速定出。交换器的埠直接连接节点或另一交换机埠,由于对家只有一个节点,没有竞争问题,可以忽略CSMA/CD法则,允许送收两线独立运作,而达成全双工运作。
全双工的线路频宽等于半双工的两倍,又省略CSMA/CD,简化电路设计。另一个最大好处是CSMA/CD协定为协调多点的送收,设定一些时序的限制,即必须考量讯号必须在最短封包传送完毕前到达最远节点,否则无法及时作出正确的冲撞动作,而讯号的传递速度上限为光速,结果是网路的直径及每一连线的长度都必须设定限制,而媒介接取层(MAC Layer)的电路的设计也须十分注意。全双工设计取消CSMA/CD,也解除大部份限制,例如半双工CSMA/CD的个别线路一定有长度限制,也有集线器个数的限制,但全双工线路没有绝对的长度限制,多半取决于信号衰减的程度,所以有可能拉上数公里,甚或几十公里,使乙太网路突破区域的限制,侵入都会网路(MAN)及广域网路(WAN)的领域。
在100Mbps的时代,半双工的技术已达极限,网路的布局设计已经有很大的限制。在1Gbps乙太网路的制定初期尚考虑半双工的技术,但标准的时序限制已不可能支应合理的线长,因此标准本身作一些修正,例如规定最短封包为512位元组,而非64位元组。但发展的结果半双工技术逐渐被放弃,而1Gbps乙太网路目前仅有交换器产品,而无集线器了。将来的10Gbps或更高的速率,一定只会有全双工的模式。可见的将来交换器的成本将逐渐降低,而终于取代所有的集线器,CSMA/CD也将成为历史。若问乙太网路除去CSMA/CD,还剩什么?答案是标准的封包格式,包含封包长度、位址格式等。这也是乙太网路的最大资产。
自动协商(Auto Negotiation)
乙太网路的发展产生许多变形,在同一电缆的两端往往有速率的不同,全双工或半双工的设定等,最初都是人工设定以达成一致,后来为实际需要,逐步发展出两端自动协商的机制,系利用实体层的特殊讯号交换彼此的能力,而协调出最佳的速率及双工的匹配。交换器晶片不必处理自动协商,那是实体层(PHY)晶片的事。但必须知道协商的结果如埠的速率、双工模式及流量控制设定等事项。
扩张树协定(Spanning Tree Protocol)
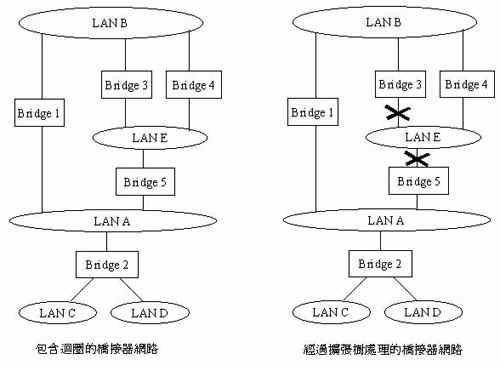
在桥接器发展的初期就发现一个问题,就是桥接器形成的网路不可有回圈。本来在集线器的网路也不可有回圈,否则讯号来回重覆传递,马上瘫痪整个网路,但集线器有一个Jabber保护机制,可以自动关闭有问题的埠,保持整个网路的正常运作。桥接器是属于网路第二层的设备,必须利用控制封包来解决,而无法直接用硬体电路。回圈造成的问题之一是桥接器处理广播及溢流封包,是向输入埠以外的所有埠发送,若网路有回圈,该封包就会循另一条路径回到原发送之桥接器,而被反覆转送无限次,进而瘫痪整个网路。
网路回圈的问题十分难查,只要有一个小地方有个本地回圈,整个网路就被广播风暴(Broadcast Storm)所席卷。为解决此问题,发明了扩张树协定(Spanning Tree Protocol)。扩张树是图学(Graph Theory)的一种观念(图七),是指在一个由点和线组成的图形中,移去若干线来除去所有的回圈,使每一点能有路径到达任意点,而且路径为唯一。剩下的点线构成一个树状图。扩张树协定使每一个桥接器利用此协定与其他桥接器交换资讯,自动使整个网路形成一个扩张树,而除去所有回圈。
乙太网路交换器既为桥接器的一种,也必须提供扩张树的功能。扩张树协定本身是由微处理器执行,但配合协定的执行,每个埠必须有阻塞(Blocking)、倾听(Listening)、学习(Learning)、转送(Forwarding)等状态,影响封包收送及位址表之处理等动作,这是交换器晶片必须提供的功能。
流量控制
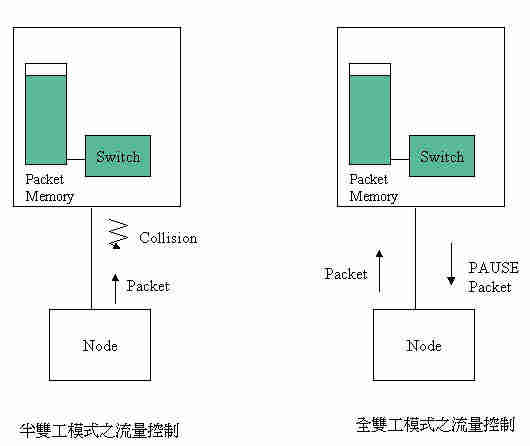
标准的CSMA/CD协定没有流量控制,封包送出后直接由接收节点收下,该节点若不胜负荷,上层的协定会处理。集线器是实体层的设备,没有缓冲器(Buffer)将封包收下,也无从控制流量。交换器的动作是将封包收下后转送,如果转送的速度不及接收的速度,或有其他埠竞争同一输出埠,则封包会在封包记忆体内快速累积。在封包记忆体用完之前,可以作流量管制,否则记忆体用完后,新接收的封包只有丢弃一途。
在半双工的埠,流量管制用模拟冲撞(Collision)的方式达成,即将流入的新封包加以冲撞,使其进入后退模式(Backoff),而达到减缓输入的效果(图八)。全双工的埠无冲撞功能,在全双工标准IEEE802.3x中定出用控制封包的方式作流量管制,即由接收端发出表示暂停的封包,送端即停止传送一段时间。收端在有空间时亦可主动送出封包要求再送。交换器具有流量控制功能者必须有这些动作。
虚拟网路(Virtual LAN)
为实用的需要,多埠的交换器往往具备分组的功能,即将一个交换器的所有埠分为互不相连的几组,各组内可以互通,但组之间不互通。每一组形成一个单独的区域网路,如此分区的主要用途是将每一区定为一个子网路(Subnet),再用路由器(Router)联络各子网路,形成公司网路,或称内网路(Intranet),而经对外的路由器连上网际网路(Internet)。
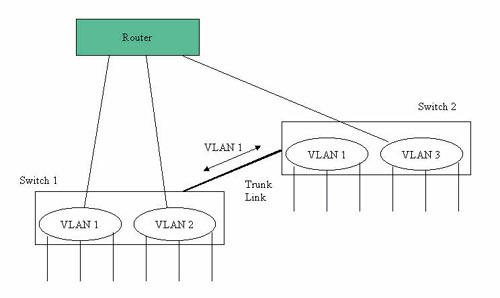
埠的分组后来又称为虚拟网路(Virtual LAN;VLAN),其实虚拟网路的种类有相当多种,视分类的标准而定,如有以埠分组的虚拟网路(Port-based VLAN)、以乙太网路位址分类的虚拟网路(MAC-based VLAN)、以子网路分组的虚拟网路(Subnet-based VLAN)、以协定分类的虚拟网路(Protocol-based VLAN)等。以埠为主的虚拟网路较简单,也有IEEE802.1Q标准规定之。在此标准中特别定了一个新的标签(Tag)栏,将乙太网路的最大封包长度扩充4个位元组,至1522位元组。标签中包含一个12位元的虚拟网路识别码(VLAN ID),使虚拟网路可以辨识。
为何需要虚拟网路标签?由(图九)可得知。原来埠的分组仅限于一台交换器内,如果一个子网路所需的埠数超过一台交换器,或为设定方便希望将一个子网路分别定在两台交换器中,如何作到?只要将相同的虚拟网路识别码设定在两台交换器的两个虚拟网路,将两台交换器的连接埠设为加标签的主干链结(Trunk),则封包到另一台交换器后可自动送到相同的虚拟网路中,将两台交换器的相同虚拟网路连为一气。
服务品质(Quality of Service)
乙太网路的缺点及优点都是其公平性。在CSMA/CD网路上所有节点都是平等的,没有谁有优先权。最近多媒体的应用则生出新的需求,希望将应用加以分类,有些资料没有时效性,可以等待交通顺畅时再送,另一些则要求时效性,如即时的声音传递,需要定时送出,不能延迟,所以收到声音封包后,必须优先处理。由于交换器内部有伫列(Queue)排定封包送出的顺序,可以作某些优先权的功能。在上述的虚拟网路标签中有3个位元可表示优先权。不同优先权的封包可置入不同的伫列中,由高优先权的伫列优先送出。每一种优先权在每埠都需要一个伫列。例如某交换器可提供四类优先权,表示每埠至少有四个输出伫列。
交换器能处理优先权者可以支应基本的多媒体通讯需求。
群播(Multicast)
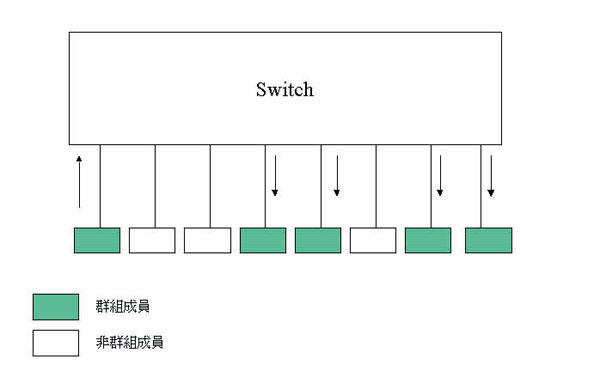
群播是利用特殊的目的位址,将封包送给一群对象,而非单一节点。广播(Broadcast)是最常用的一种群播,所有节点均须收下广播封包,再判定是否包含需要的资讯。由于广播会使所有节点疲于奔命,其使用必须十分节制,所以需要一群节点同时接收的资讯多用非广播的群播来发送,节点内的电路可以自行判定是否接收特定的群播位址,而不会接收不必要的资讯。乙太网路的特性十分适合群播,因为封包发出后,会送给所有节点,各节点由目的位址判断是否接收。群播的封包假如改用个别发送,则占用的频宽会是群组成员数的倍数。早期广播及群播仅用于高层协定建立最初连系的工具,或伺服器、路由器等广播网路管理资讯等,所占频宽不大。然而多媒体应用崛起后,群播被视为即时影音广播的利器,则所占的频宽会影响网路的运作什巨。
交换器处理群播,最先仍采取广播的方式,即收到群播封包后以溢流的方式发出(图十)。但若群组的成员不多,这种方式相当不经济,所以后来定出群播注册的方式,即参与群播的节点发出注册通知,交换器收到后即知该埠有群播成员,每一交换器的成员名单再以广播的方式通知所有的交换器。当群播封包收到后,交换器只会将该封包发送到含有群播成员的埠。目前群播功能在第二层有GMRP协定,第三层有IGMP、DVMRP、PIM等协定,负责群组的注册与传播。交换器亦有提供IGMP窥探(IGMP Snooping)功能,即借捕捉第三层群播注册的IGMP封包,来设定本身的群组成员。群播功能与封包转送有关,交换器晶片必须有此设计,系统才能支援此功能。
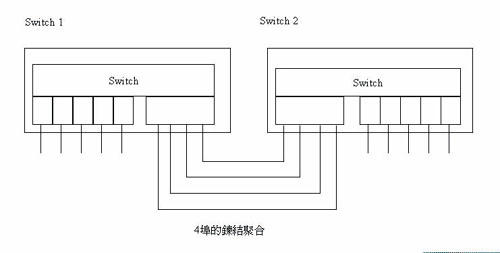
链结聚合(Link Aggregation)
在扩张树协定中,平行的链结视为回圈而借阻塞(Blocking)状态移除多余的链结,使两交换器间仅有单一链结,而避免封包绕圈的问题。多余的链结仅作后备用途。如此一来相当于浪费许多频宽。为有效利用平行链结的频宽,交换器厂商设计了链结聚合(Link Aggregation)的技术(图十一)。
观念上是将平行的链结视为同一链结,发送端将封包平均利用各平行链结发出,而收端则将各平行链结收到的封包聚集一处处理,不会由另一路绕回。在两方都有此设定时,由扩张树协定视之,可作为一埠,而非多埠,因而没有冲突。桥接器标准规定同一会谈的封包顺序不可以改动,所以封包分配给平行链结时通常将目的位址及来源位址作运算来分配,使同一组的目的位址及来源位址必定走同一链结,解决顺序的问题。
埠导引(Port Mirroring)
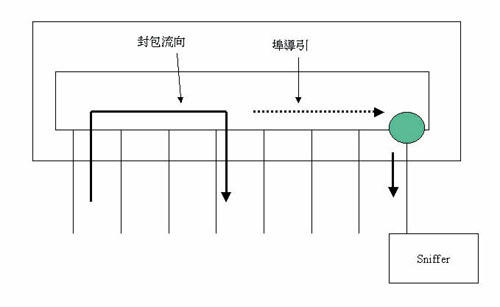
在传统乙太网路中,由于属广播性质,每一节点均可收到全部的网路通讯状况,任一节点只要将其乙太网路埠设定为全收(Promiscuous)状态,即可收到所有网路封包,所以网路若发生问题,借网路分析仪(Protocol Analyzer)或具此功能的软体,就可以观察所有的通讯而容易地发现问题所在。相对地,任何人均可监听所有资讯,导致安全性不足。在集线器成为主流后,因而发展了防窃听(Eavesdrop Prevention)功能来防堵此安全漏洞。
交换器则本身就有过滤本地封包的功能,封包只会送至其目的埠,而其他埠不会收到,安全性没有问题,但管理上会有不便。若某埠发生问题时,除非将其线实际拆下,插入网路分析仪,否则无法观察该线路的收送状况。交换器特别设计此功能,可借网路管理的设定,将某一埠收送的封包复制一份到一设定的埠上,而该埠可以接上网路分析仪加以分析(图十二)。
第三层交换器(Layer 3 Switch)
第三层即网路层,网路层负责将各种不同的区域网路、都会网路、广域网路等连接起来,成为一个大网路。目前风行全球的网际网路(Internet)就是最成功的例子。网路层提供一个统一的定址方式,使远在天边的两个节点能互相取得联系,最重要的是订出整个网路的路由(Routing)方式,使网路封包离开原节点后,经过一连串的路由器(Router)转送,最后到达目的地。
如此看来,路由器与桥接器有许多相似之处,但这只是表面上的。桥接器的基本假设是封包可用广播的方式送到目的地,因此若有未知方向时,就用溢流的方式解决,所以桥接器只是尽力做到过滤的功能,而没有义务负责封包的去向。发送封包的节点不须知道桥接器的存在,而是假设目的节点就在身旁,桥接器则是担任一个透明的角色,在幕后将封包送到目的节点。以定址而言,乙太网路位址无需考虑网路的结构,只须每个位址均能唯一即可。这种作法对较小规模的单一区域网路而言很方便,但绝对无法用来建构全球网路。以网际网路的庞大,如果允许盲目传送,很快就会瘫痪,因此网路层的封包,必须是以主动的方式转送,每一点都需要知到下一点的所在。
每一种网路层协定的设计各有不同,这里仅举IP协定为例。 IP路由器的转送方式是由收到的封包检查其目的网路位址,查路由表(Routing Table)判定封包的输出埠而将其送出。封包的目的位址如果无法查出应送的方向,则该封包被丢弃,并发出ICMP错误报告封包给原发送者。
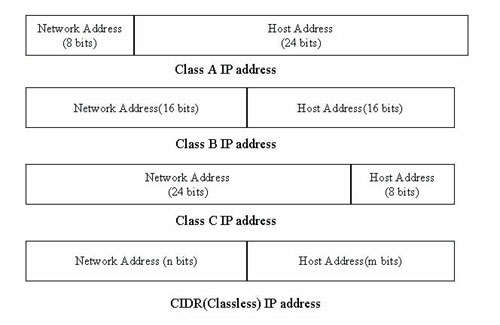
IP位址的分配也是转送机制的一环(图十三)。每一个IP位址分为两个部份,前面一部份称为网路位址(Network Address),代表网路的识别码,后半部称为节点位址(Host Address),代表节点本身。第四版IP协定(IPv4)的位址为32位元,网路位址与节点位址的位元数则不一定。过去的标准分为A,B,C等等级,代表不同大小的网路,但由于实际管理的需要,往往用子网路罩(Subnet Mask)来设定不同的位元分配,近来由于IP位址在网际网路的爆炸性发展下已不够分配,乃采取新的CIDR标准,即允许任意分画网路位址与节点位址的位元数,以将IP位址作更弹性的分配。
IP位址的分画有什么重要呢?每一个路由器的埠连接的就是一个子网路,其中每一节点都拥有相同的网路位址,及不同的节点位址。子网路的位址就定义在埠上,一个封包进入一个路由器后,正常情况有两种可能,一为目的位址的网路位址部份与某一埠的子网路位址符合,表示该封包已到达终点,应由该埠送出,到达目的节点;另一种情况是查路由表后,找到送到该目的所应利用的下一路由器与应送出的埠,将封包送至下一站。由于IP位址的位元数有限,所以子网路的节点数应有较实际的估计,使用较合理的位元数作网路位址。由以上可知,路由的方式与桥接有极大的不同。
由于路由器的硬体架构与桥接器十分类似,只是封包的解读与转送规则不同,所以其发展的途径与桥接器十分相似。最初以一些硬体的设计来辅助主处理器,然后以特殊设计晶片来接管,也称为交换器:第三层交换器(Layer 3 Switch),如第三层交换器仅提供IP协定,称为IP交换器。
在广域网路的产品中也有IP交换器,是非同步传输模式(Asynchronous Transfer Mode,ATM)交换机技术的IP交换器,虽然也同样是路由器的加强版,但ATM技术与乙太网路有很大的不同,两种交换器的设计及解决的问题不同,所以在此按下不表。第三层协定的封包处理,程序如下:
(1)解读封包的资料链层,判定第三层协定的种类。乙太网路封包的位址栏位后,有一个型态栏(Type),通常是用来选择第三层协定,例如0800h代表IP协定,8137h代表IPX协定,819Bh代表Appletalk协定等。判定协定后,再按照各协定的规则处理其讯头。
(2)IP协定的转送是看IP讯头中的IP目的位址(Destination IP Address),根据其中的网路位址栏位来决定送出的埠。如前所述,网路位址栏的长度是不定的,所以处理上比乙太网路位址表更复杂。在路由表中每一个网路位址均记载其位元数,而由IP目的位址本身无法得知其中网路位址的位元数,必须与每一个位址表中的每一列比较,由于各列网路位址位元数不一,可能有不只一个通过比对,此时必须选择位元数最多的一列,这种比对称为最长字首比对(Longest Prefix Match)。由位址表比对出的列选出应转出的埠。
(3)转送的对象有两种情形。目的子网路在某埠上时,应直接送至目的节点,否则目标是下一个路由器。无论如何,封包送出时仍必需通过第二层,即仍须在第二层的讯头上填上下一站的乙太网路位址,方能到达。 IP层在这种转换时倚赖一种ARP(Address Resolution Protocol)协定。 ARP协定根据IP目的位址,在区域网路上发出广播的ARP讯息。拥有此IP位址的节点会发出回答讯息,将本身的乙太网路位址回报。ARP所得的IP与乙太网路位址的对应表会储存备用,所以ARP讯息不必每次发出。
(4)IP协定讯头有些栏位必须处理,以符合IP协定的规则,例如有一个生命时间(Time-To-Live;TTL)栏,是用来防止网路无限回圈的,必须在封包经过时将其减1,而TTL为0者不得转送,若非已到达目的者应予丢弃。另外,IP讯头有检核码,由于讯头已修改,必须重算。
在第三层的加速问题,最显而易见的问题是最长字首比对(Longest Prefix Match)。由于位元数不定,一般的散列法(Hashing)无法使用,但顺序比对及二元比对又不足用来处理每一个经过的封包。在路由器的设计上,这原就是一个核心问题,硬体加速技术要考虑硬体的可实作性,限制就更多了。
最长字首比对法目前已有多种方式可达成,有些也能用硬体实作。但总之比第二层位址处理的困难,也可能有些限制,例如需要大量记忆体,或资料结构复杂,不易修改更新等。
以内含定址记忆体(CAM)而言,一般的CAM也无法使用,而必须使用三元式(Ternary)的CAM,即每位元可有3个状态,以便表示不定长的内容。由于网际网路的发展,及技术的相对难度,虽然目前这种CAM成本仍高,未来应用的可能性很大。目前一些号称IPCAM的晶片,主要就是提供这种功能。
硬体成本较低的做法是避开硬体的最长字首比对,仍用软体解决,但用硬体处理ARP对应表。这种作法虽然较全硬体处理无效率,但所差并不多。一个交谈的第一个封包可能需要软体处理,因为该IP目的位址并未出现在硬体ARP表中。在软体处理后,新的IP位址填入表中,此后的各封包即可利用此ARP对应由硬体转送,而不再透过软体动作。这种一次路由、多次交换(Route Once, Switch Many)的作法实际的效能和其他方法是差不多的,又可以类似第二层的完整比对(Exact Match)法,用散列法等比较简单的方式达成低成本设计。
路由表的建立可由事先规划,或透过路由协定(Routing Protocol)彼此交换所知的讯息。由于网际网路的广大,每一个节点能做的规画很有限,主要还是要靠路由协定来维护网路上的路由资讯。 IP路由协定有两类,一种是在一个网域内部的,称为内闸路协定(Interior Gateway Protocol,IGP),一种称为外闸路协定(Exterior Gateway Protocol;EGP),是用来交换网域间的资讯的。IGP较常用的有RIP(Routing Information Protocol),及OSPF(Open Shortest Path First)等协定,而EGP则主要用BGP(Border Gateway Protocol)协定。路由协定是用来交换路由器间的资讯的,通常是用软体来执行,而不可能用硬体加速。
第三层交换器有不少配合的功能,IP群播是其中重要的一个。 IP群播的设计很早就很完备了,但实用上一直在实验阶段,原因是过去需求的诱因不大,过去的硬体能力也不足以支应IP群播的效能需求。目前情况改变了,由于多媒体应用的风潮,IP群播应用已达实用阶段,而硬体技术的进步则使这种应用逐渐变成可行。前述有关乙太网路的群播功能,事实上主要还以IP群播的应用为主。
一般第三层交换器可能会同时提供其他协定的路由功能,例如IPX协定,Appletalk协定等,这些协定与IP协定的规则并不相同,所以必须针对各协定设计其路由功能及路由表的查对功能,使交换器的功能更加复杂,成本更高。是否提供这些功能,就是设计上的考量了。
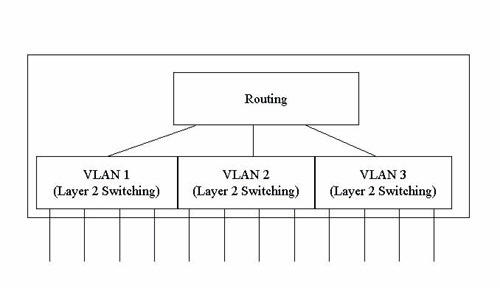
多层次交换器
一般路由器通常埠数不多,因为埠所连的就是分别的子网路,而一般企业并不需要设定许多子网路,通常仅照部门或楼层作大体的区划。但目前交换器设计的埠数可以相当多,如果第三层交换器仍将每一埠设定分别的子网路,这种设计并不实用。比较可行的是将第二层和第三层功能一同考虑,规画出多层次交换器。如(图十四),第二层交换器利用虚拟网路区分子网路,每一个虚拟网路组规画为一个子网路,第三层交换器则为虚拟网路间之路由器。当然,这是观念上的表示,在实际的逻辑设计上可以一气呵成。
多层次交换器的功用
以实用的角度来看,第二层交换器已经提供相当大的频宽给每一个埠,为什么在乙太网路建构中规画第三层的交换呢?换言之,为什么不将整个乙太网路规画成一个子网路,免去第三层的麻烦呢?理由如下:
(1)第二层交换器无法克服的是广播封包的问题。在桥接机制下,广播封包必须无条件的送达每一节点,所以一个桥接器的网路称为一个广播域(Broadcast Domain)。在节点个数增多后,广播封包的比率会增加,到达一个百分比后,网路的效率会受影响,而且广播封包每一个节点都必须接收处理,如此会全面降低每一个系统的效能。减少广播封包的方法是将网路分为多个子网路,因为广播封包不会跨子网路传送。
(2)系统管理者基于管理的方便,会希望将网路分为若干相隔离的子网路,以减少各群组的互相干扰,或机密讯息泄漏的机会。
第四层交换器
第三层交换器已解决网路层的路由问题,为何还有第四层及以上的交换器?第四层是传输层(Transport Layer),强调的是两节点的应用程式间通讯管道的建立与使用,换言之,第四层功能已关切到个别的应用,而不只是节点间的通讯。原来在路由器的设计上,有一些方便管理的功能,例如过滤位址及应用的安全功能等、后来对服务品质(Quality of Service)的重视,开始加入有关频宽管理的功能及RSVP协定等。这些附加或新加的功能,都强调对不同用户及应用的辨认及差别处理等,所以在交换器加入这些功能,就称为第四层交换器。第四层交换器所具备的功能有:
(1)第二、三层交换器的桥接与路由等功能。
(2)讯流分类功能(Flow Classification),即能观察第二、三、四层讯头,作适当的分类。分类的方式可能分为几个等级(Class),或细分为微讯流(Microflow),即用三、四层讯头中的五个栏位辨识封包所属的会谈(Session),赋与一个讯流编号(Flow ID),以作后续的处理依据。
(3)服务品质(Quality of Service)的管理:根据封包所属的类别,给予一定的通讯品质,如频宽、延迟等的保证。以微讯流的方式管理通讯品质,可以将每一个会谈的通讯品质控制得相当准确,然而因为需要在过程中保留沿途的所有路由器的频宽,在网际网路的上面运用的可行性不大,所以多只限于在小范围内的应用。以分等级的方式处理服务品质的问题,称为有区别服务(Differentiated Service),是目前在大网路上实施服务品质管理比较可能的方式,。
(4)流量管理:在一些特别的设计中,交换器可以主动运用TCP协定的流量控制(Flow Control)功能来控制各微讯流的流量,以调整流入交换器的封包率,而不待进入后才作处理。
(5)政策(Policy):根据不同的网路使用者及应用的需求,设定赋与的频宽,或设定进入的管制,不允许某些使用者进入等。管理者设定的规则(Rule),转换为实际交换器的操作行为。
第四层以上的网路功能,虽然有一些标准,但由于层面上相当广泛,在产品提供的功能上个别化的倾向很大。号称第四层以上的交换器目前在定位上仍趋向较高阶的使用者,而不强调产品的普及化。
在第四层以上的产品设计,额外考虑的是每一个封包必须检的栏位更深,需要额外的规则表(Rule Table)以为比对,而频宽管理上要能追踪许多的微讯流,管理其个别的频宽使用量,在设计上也是很大的挑战。在多层次交换晶片的设计上,多半会提供某些第四层的处理功能,但如何订出实用的软体功能,以达成设计的目的,是第四层产品的课题。
结论
交换器是目前乙太网路发展的主流方向,目前国内的努力,大多数仍在提供更具成本优势,更高埠数的产品,以争取更大的市场占有率。这诚然是国内竞争优势的展现,然而具备网路管理功能,以及第三层以上的交换功能的交换器,能够提供更高的附加价值,若能成功打入企业市场,其发展更不可限量。站在产业升级的观点上,如何提升产品的位阶,增加竞争力,是企业求生存发展的不二法门。这也是高阶交换器一直受到嘱目的原因。要发展更高阶的产品,除将系统晶片化(System-On-Chip)外,软体的角色也是关键,这也是国内亟须加强的方向。