在本篇文章中,笔者将介绍何谓网路资料探勘、并针对网路资料探勘系统的架构与规划、网路资料探勘技术所遇到的瓶颈与挑战,以及网路资料探勘技术未来的走向与趋势做一个详细的说明。
电子商务与网路资料探勘
由于网际网路(Internet)与全球资讯网(World Wide Web)的盛行,网路使用人口也急速地成长,并成为从事商业交易、行销,以及广告等商业行为的重要工具及媒介。许多原本不是在网路上的活动也藉由网路之便,迅速地在网路上走红,电子商务(Electronic Commerce)就是一个很明显的例子。
电子商务系统即所谓的 “网路商店”( Cyberstore)或 “线上购物”(On – Line Shopping)系统。它藉由网际网路的双向沟通,使得企业可将产品、服务和广告等讯息存放在企业所建置的网站上,让消费者可藉由企业所建置的网站伺服器(Web Server)获得所需的资讯,同时也可在此网站上订购商品或留置讯息。因此,电子商务系统提供了一种无国界、无时差的业务管道,也让它在国际市场上占有非常重要的商机。
然而,许多的电子商务网站仅是将公司与产品的简介等作成单纯的网页,并以静态的方式提供资讯服务,却没有考虑到顾客真正的兴趣与喜好,也没有与顾客间形成互动,以提供顾客真正感兴趣的商品资讯,这跟一个顾客实际到一家商店购物的感觉是非常不同。
一个顾客实际到一家商店购物,店员会针对顾客的需求,来帮助顾客寻求或详加解说商品。如果仅是提供静态的服务,只可以说是达到详加解说商品的目的而已,顾客仍需花费更多的时间和精力,去搜寻自己真正想要的商品。因此,了解您网路上的顾客是谁?他们都在您的网站上做什么?就变成目前电子商务网站急需具备的基本功能。要做到这些事,则必须有赖于网路资料探勘的技术。
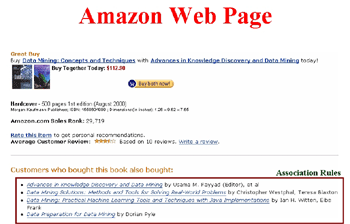
举例来说,(图一)是亚马逊(Amazon)书店的购物画面,在这个画面中,一个顾客想购买两本有关资料探勘的书。网页除了呈现这两本书的内容外,在网页下方也有一个Also Bought的推荐,其目的就是藉由此种方式来达到书籍的交叉销售(Cross – Sell)。而要达到此功能,则必须在顾客以往的网路交易记录上,进行资料探勘中的关联规则(Association Rule)技术运作。换句话说,我们可以利用资料探勘中的关联规则技术来找出顾客购买网路产品之间的关联性,并利用此关联性来达成交叉销售的目的。
一般来说,网路资料可细分成下列几个部份:
- * 网页本身的内容(Content of Web Pages)
- * 网页本身的结构(Intrapage Structure of Web Pages):网页本身的结构通常是以HTML或XML的方式来表达。
- * 网页间的结构(Interpage Structure of Web Pages):网页之间通常是以超连结 (Hyperlink)的方式来相互连接,形成网页结构。
- * 使用者参与网路活动的记录(U sage data that describe how web pages are accessed by visitors)
- * 使用者的个人资料(User Profile):使用者的个人资料通常包含使用者的背景资料(Demographic)、使用者的网站注册资料(Registration Information),以及使用者在Cookies上的资料。
网路资料探勘技术就是植基在这些网路资料上,去发掘顾客的网路行为。
网路资料探勘的系统架构与规划
目前市面上有许多网站分析的工具(Web Analysis Tools),如Web Trends (http://www.webtrends.com/)、Open Tracker(http://www.opentracker.net/),及Net Genesis( http://www.netgen.com/netgenesis/)等。然而这些网站分析工具大多集中在统计顾客在网站上的资讯,如那个网页最受顾客的青睐,它的点选率(Page Hits)有多高、来浏览网站的顾客都是从那个地方连结过来、一星期中的网站每天的流量有多少等。这些资讯虽然重要,但对于我们要全面了解顾客而言,它们还是不够。
同时,点选的次数并不代表造访顾客数,点选次数多的网页也不一定代表来浏览的顾客多(因为一个人可以点选多次),也不一定是热门的网页(因为网页被点选多次有时是因为它在网站中的位置(Location),而不是它的内容(Content))。首页(Homepage)就是一个最好的例子,在一个网站中,首页通常被点选的次数是最多的,这是因为它是入口的网页,而不是因为它的网页内容。
通常,一个完整的网路资料探勘系统必需包含两个部分:
- 1. 网路资料的收集(Web Access Data Collection)
- 2. 网路资料探勘的方法(Web Pattern Mining)
网路资料收集,在于强调收集顾客在网路上的一举一动,并区分顾客。而网路资料探勘的方法则强调在伺服端所收集到的资料上,发掘出隐含在资料内的顾客行为。在网路资料的收集上,一般有下列两种收集方式:
- 1. 在伺服端收集资料(Server – Based Data Collection)
- 2. 在客户端收集资料(Client – Based Data Collection)
由于伺服端在收集资料时,是收集所有人在网站上的行为,因此将来在这种资料上做探勘时,会发掘出大众化的行为模式。例如可能会发掘出 “大多数的顾客通常会先浏览网页D,然后浏览网页A和购买产品P,最后会到网页C” 等大众化行为。
而客户端在收集资料,由于是收集某个人在网站上的行为,因此将来在这种资料上做探勘时,会发掘出个人化的行为模式。例如可能会发掘出 “顾客T在这个网站上,通常会先浏览政治性的网页,然后再到讨论区” 等个人化行为。
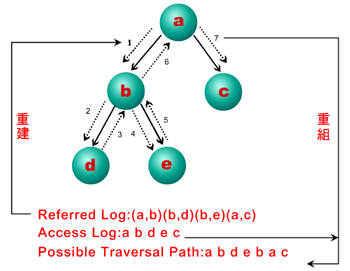
伺服端的资料收集通常是藉由整合网站伺服器(WWW Server)中的Access Log及Referred Log获得。 Access Log中记载使用者在什么时间(例如:12/Apr/ 1999:11:31:40),从那个Domain Name(例如:flea.cs.kobe-u.ac.jp)或IP(例如:163.221 .174.24)连线到这个网站,以及存取什么资料(例如:GET/dasfaa99/New.gif)。 (图二)便是Access Log的一个范例。
在Referred Log中,会以配对的方式记载使用者目前的网页及即将存取的网页。例如假设目前的网页为A.htm,而使用者即将存取B.htm,则(A.htm、B.htm)这个配对就会被存进Referred Log中。
藉由整合Access Log和Referred Log的动作中,网管可以得到使用者完整的浏览网站的资料。 (图三)为一个使用者浏览网站的例子,在这个例子中,使用者先浏览a、b、d,然后回到b、e,然后再回到b、a,最后到c。 Access Log和Referred Log的内容也分别在(图三)中呈现。网管可利用Referred Log重建网站架构,再搭配Access Log将使用者可能的浏览路径(Possible Traversal Path)重组出来。
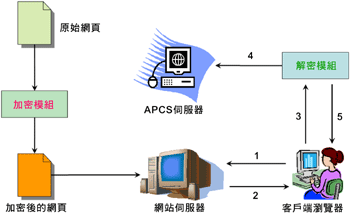
客户端的资料收集通常是先安装一个客户端的程式,然后再藉由这个程式在客户端收集顾客资料并回传到选定的资料库中。国立台湾大学陈铭宪教授实验室所发展出的Access Pattern Collection Server(APCS)系统即为这方面的代表。如(图四)所示:
在(图四)中,每一个原始网页均在加密(Enciphering)后,才放置在网站伺服器中。当使用者从客户端的浏览器(Web Browser)要求看某一个网页时,网站伺服器便会将加密后的网页下载至客户端的浏览器中。此时,如果使用者没有安装客户端的资料收集程式则会看到乱码,网页无法正常显示,但如果有安装,则此程式首先会至APCS伺服器记录使用者存取那个网页,然后再将加密后的网页解密(Deciphering),最后再将解密后的网页正常显示在客户端的浏览器上。
基于这些收集到的资料,网路资料探勘就是要将隐含在这些资料中的顾客行为发掘出来。一般常见的网路使用探勘方法有下列几种:
- * 关联规则(Association Rule)
- * 路径浏览型样(Path Traversal Pattern)
- * 网页浏览型样(Web Traversal Pattern)
- * 网路交易型样(Web Transaction Pattern)
在电子商务的网路环境中,顾客购买商品间之关联规则(Association Rule)的找寻是一个重要的商机。所谓的关联规则,如下所例:
- * 喷墨印表机,墨水匣 =>印表纸(可信度=80%,支持度=30%)
其意义为:在所有的交易中,有30%的交易会同时购买喷墨印表机,墨水匣与印表纸这三项产品;而在所有购买喷墨印表机与墨水匣的交易中,有80%的机率会一起购买印表纸。当我们提供这样的资讯给网站的经营者时,他们便可依此资讯来做出新的决策,以增加其交叉销售的机会。
探勘路径浏览型样(Path Traversal Patterns))则是想要在电子商务的网路环境中,寻找出大多数顾客的浏览行为。当我们了解大多数使用者在网路上的浏览行为后,我们便可以提供这些资讯给网站设计者,以改善网站的设计。举例来说,假设我们探勘出大多数顾客经常浏览的路径为<A、B、A、C>。这代表大多数的使用者浏览网页A后,会去浏览网页B,然后回到网页A,最后会去浏览网页C。
在这样的探勘结果下,一条由网页B直接到网页C的连结则是有相当的必要性。同时,这项技术也可用来改善Proxy Server在预取(Prefetching)及快取(Caching)上的效率。举例来说,假设我们探勘出大多数顾客经常浏览的路径为<A、B、C>,则在使用者浏览网页A的同时,Proxy Server便立即利用此项讯息将网页B与C预取进来,并放置在使用者的快取中,以便使用者继续浏览网页B或C时,能立即获得所需的网页、提升网站的效率。
然而,传统探勘路径浏览型样的演算法都有一个限制:他们只能发掘出简单的路径浏览型样(网页不能重复的出现在同一个路径浏览的型样之中)。不过在电子商务的网站中,非简单浏览序列则更能发掘出顾客的心理状况,且能提供更多的资讯。因此,网页浏览型样(Web Traversal Pattern)的方法也陆续在网路资料探勘领域中被提出,并用来产生非简单的浏览序列。
近来,网站经营者感到兴趣的是顾客在购买相关产品时,是依照何种的浏览路径来完成购买这些商品的程序;而只靠单纯的商品间探勘关联规则,及顾客浏览型样并无法满足网站经营者在这方面的需求。为了克服只单纯的探勘关联规则或浏览型样所带来资讯不足的缺点,网路交易型样(Web Transaction Pattern)的研究也逐渐受到重视。
网路交易型样技术又称为网页浏览型样之关联规则技术,它可同时发掘使用者在浏览网站与购买商品之间的关联性。举例来说,(表一)是记录使用者浏览网站与购买商品的资料库;(表二)是利用网路交易型样技术列出部分的探勘结果。其中<ACAE:C{2}=> E{3}>是表二中的一个网路交易型样,它的意义是在33%的交易中,顾客会先浏览A、C(购买产品2) ,然后再回到A,最后到E(购买产品3)。而当顾客已浏览A、C、A并在C购买产品2之后,100%的顾客会浏览E,且同时购买产品3。
表一
|
交易编号 |
浏览路径 |
购买商品 |
| 1 |
BECAFC |
F{1} |
| 2 |
DBACAE
|
C{2}, E{3} |
| 3 |
BDAE
|
|
| 4 |
BDECAFC |
F{1} |
| 5 |
BACAE |
C{2}, E{3} |
| 6 |
DAC |
C{2} |
|
网路交易型样 |
支持度 |
信赖度 |
| <BECAF: F{4}> |
2/6 |
2/2 |
| <BACAE:
C{2} ==> E{3}> |
2/6
|
2/2 |
| <ACAE: C{2}
==> E{3}> |
2/6
|
2/2 |
| <ECAF:
F{4}> |
2/6 |
2/2 |
| <BAE: E{3}> |
2/6 |
2/5 |
| <CAF:
F{4}> |
2/6 |
2/2 |
| <DAC: C{2}> |
2/6 |
2/4 |
| <CAE:
C{2} ==> E{3}> |
2/6 |
2/2 |
|
<AC: C{2}> |
3/6 |
3/6 |
由(表二)可以看出,网路交易型样技术在结合网页浏览型样(因为它探勘的结果允许网页可重覆出现– 非简单浏览序列)及关连规则的分析后,可以发掘使用者在浏览网站与购买商品之间的关联性。
网路资料探勘技术所遇到的瓶颈与挑战
在伺服端的资料收集上,我们通常会遇到两个问题:
- 1. 代理伺服器的使用(The Use of Proxy Server)
- l2. 快取的效应(The Effect of Caching)
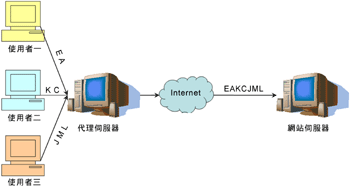
代理伺服器(Proxy Server)的使用会造成网站伺服器误记要求网页的来源为代理伺服器;以(图五)为例,由于三个使用者(一个要求网页E和A、一个要求网页K和C、一个则要求网页J、M和L)都联结到相同的代理伺服器,并透过代理伺服器联结到网站伺服器,所以网站伺服器会记录下来这台代理伺服所器要求的网页E、 A、K、C、J、M和L;因此记录会发生错误,而其探勘的结果也会不正确。快取的效应则会造成部分所要求的网页,直接从使用者端的快取中取出,而网站伺服器的记录则会呈现断断续续的现象,造成无法藉由Access Log及Referred Log推断出使用者的真正的浏览路径。
不过由于网路技术的高速发展,就目前而言,上述部分的问题已获得解决。举例来说,我们可以使用较先进的网站伺服器(HTTPd的通讯协定要在1.1版之后),即可记录到代理伺服器背后的来源电脑,以解决网站伺服器记录错误的问题,或是利用有支援Section ID的程式语言如Active Server Pages(ASP)也可解决上述部分的问题。基本上一个Section ID代表一个浏览器,并不会受到代理伺服器的影响。
然而还是有些问题暂时是无法解决的,例如当多人共用一台机器时,我们便无法区分这些使用者。另外,当一个人使用多台来源机器时,我们也无法区分这是否为同一个使用者;同时,网站伺服器也只能记录使用者在自己伺服器中的行为,当使用者离开目前的伺服器而转移到别的伺服器时,我们便记录不到使用者在其他伺服器的行动,而这些问题还需更先进网路技术的支援才能解决。
另一方面,快取(Cache)的效应已能透过在网页中加注过期标签的方式,解决网站伺服器记录不完整的问题。我们可以在网页的<head>及</head>间加入以下的标签:
<meta http-equiv=="Pragma" content="no-cache">
<meta http-equiv=="Expires" content="Tue, 01 Jan 1980 1:00:00 GMT">
如此一来,使用者在每次要求网页时,一定会跟网站伺服器要,而不会直接从使用者端的快取中取出。许多线上的系统也利用此种方式,保证不会让使用者看到过期的资讯。例如,使用者绝对不会在中时电子报看到昨天的新闻,因为它们用的就是这个技巧。
客户端的资料收集相对于伺服端的资料收集是相当准确且详尽,它可以很容易的区分使用者,因为每个使用者都需经过注册的手续才可使用此程式。它也可记录到使用者在浏览器的所有行为,而不仅止于某台网站伺服器。
然而,它有一个严重的缺点就是使用者隐私权的问题。当要安装一个程式时,使用者通常会裹足不前,因为害怕程式收集到非自己所能预期的资料,而这也是为什么APCS系统要先将资料加密,以强迫使用者必需安装程式,才能正常运作的原因。虽然伺服端的资料收集也有隐私权的问题;然而,使用者并不会感觉到,也不会有安装软体的动作;因此,情况较没有那么严重。
在网路资料探勘的技术上,就目前开发出的技术而言,需要再加速探勘所需的时间(目前的方法仍不够快),以及再开发更多的方法(目前的方法仍不够多) ,以快速地提供决策者更多的资讯与知识。
结语
了解一个顾客在网站上行为是十分重要,网路资料探勘(Web Mining)的技术提供了一个了解客户的可能管道。利用网路资料探勘技术,我们可以重新规划、组织网站,以方便顾客浏览网站;我们也可以利用它来增进网站的效能、决定广告出现的位置,最重要的是它还能帮助我们增加商机。
在未来的走向上,于资料的收集的部分我们要密切注意新的网路技术。更先进的网路技术会使资料的收集更加容易与精准。目前网路资料探勘的方法,是朝向渐进式探勘(Incremental Mining)的方向来进行,在网路浏览的资料库中,随着时间的推进,资料量是会持续地扩增。相对于原始的资料量来说,其所增加的资料量可能根本微不足道,所以我们是否有必要为了这些小小的变动,再将全部的资料重新探勘一次呢?
不过我们若是不重新作探勘的动作,最后的分析结果就有可能会因此而产生误差。所以在资料库更新后,是绝对有必要重新作探勘,但又考虑其探勘时间的浪费,因此渐进式探勘的方法就十分重要了。渐进式探勘的主要精神为利用过去探勘的结果,并针对其新增的资料,进行更进一步的探勘动作,以增进其探勘的效率,至于要如何达成,则有赖专家学者作更进一步的研究了。
<作者为铭传大学资讯工程学系副教授>
|
|
 |
远距教学的生存和发展将取决于能否提供个性化的教学服务,Web
Mining技术使个性化的远距教学成为可能。本文就Web Usage Mining技术在个性化远距教学系统中的应用作了探讨和研究。相关介绍请见「Web
Usage Mining在远距教学中的应用」一文。 |
|
本文揭示了未来数位图书馆中图书馆员进行资讯服务的一种方式,叙述资料挖掘和WEB挖掘的基本原理和方法,并强调图书馆员应掌握资料挖掘这项新技术的必要性。你可在「资料挖掘
– 图书馆员应掌握的基本工具」一文中得到进一步的介绍。 |
|
目前许多电脑软体结合了网路伺服器和资料库所记录的网站访客上网资料或网站消费者的交易资料,提供「统计性质」的汇总报表,而网际探勘(Web
Mining)则是帮助经营者来进行决策性的判断。在「网站经营利器」一文为你做了相关的评析。 |
|
|
 |