因特网的蓬勃发展,造成了信息急速地扩张;在这一波变革中,人类正快速地将现实生活中的信息,如报纸,杂志,书籍等,都延伸至虚拟的因特网空间中。而虚拟的因特网空间也因为人类的高度的依赖,而变成现实生活的一部份。
在追求速度的竞争环境中,面对因特网中大量且多样的信息,如何快速且有效率地找到自己想要的信息,俨然是一项重要的课题。而搜索引擎在定位上,也从单纯个人信息检索的位阶,跃上了企业内部知识管理工具的重要角色。
搜索引擎的应用层面相当广泛,主要是针对不同的数据源(网络资源)而有不同的应用,在Internet 中常见的网络资源为 web page、BBS、news等。另外,搜索引擎也不再是一个被动的查询工具,而在结合其他网络服务的情况下,已从被动的查询工具变为一个主动的信息收集者。
本文将针对因特网的搜索引擎来介绍其基本架构、功能及其应用面。
搜索引擎基本架构
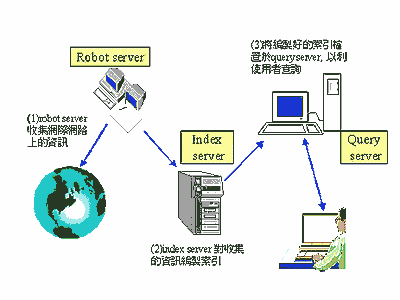
因特网的搜索引擎,其运作大概是这样子的。首先搜索引擎必须能根据我们所要搜寻的网络资源进行数据收集;例如,当我们要对新闻进行检索时,搜索引擎就必须把这些新闻全都收集回来。接着,搜索引擎必须把这些收集回来的数据,进行一番处理。如果重复的数据是没有意义的话,搜索引擎在这一部份主要的工作就是去除重复的数据;然而有些情况下,重复的数据可能会赋予不同的意义,在这情况下,搜索引擎就不会重复的数据删除。而对web page全文检索而言,通常也会去除html的卷标(tag),以确保有效数据量为最大。第三个步骤就是对处理过后的数据,进行索引的编制,而编制成一个索引数据库,以供用户来查询。值得特别注意的是,能够处理中文的搜索引擎,通常会在这一部份加入一些「同音」及 「同义词」的功能;因此,会使编制出来的索引数据库比原来的数据大了许多。整个搜索引擎的实际运作,如(图一)所示。
在逻辑上,整个搜索引擎的服务系统,是由「robot server (spider)」、「Index server」及「Query server」等服务器来组成。然而在实际应用上,并不一定会把这些服务系统放在三台不同的计算机上,而会视实际数据量的多寡、网络带宽、计算机硬件等级、搜索引擎编制索引所需时间及处理用户查询的响应时间(response time)等因素,来调整这些服务系统所需使用的计算机数目。常见的一种情况是,由于因特网上的数据量相当大,为了以更短的时间来收集这些网络资源,搜索引擎会启用更多的spider 程序或更多的robot server 来收集这些网络资源。因此,对于一个好的搜索引擎而言,除了系统稳定、执行速度快,查询结果精确等条件外,它也必须具备横向扩充的功能;也就是可以支持多台robot server 去收集网络资源,支持多台index server 同时来编制索引档,当然也必须支持多台query server 以平衡用户查询负载(loading)。
从理论来看,搜索引擎有四个主要的部份:
(1) 数据搜集子系统:
数据搜集子系统,乃是用来搜集网络上之信息。一般通称网络蜘蛛,也就是我们前面所提到的spider 或robot server。
(2) 数据分析管理子系统:
数据分析管理子系统,可用来过滤分析摘要转换或管理数据,并可去除重复多余的数据。如果是要对网页进行全文检索的话,通常在这一部份会保留所有实际的数据;另一种可能是,搜索引擎并不对网页中每一文字进行全文检索,而是只对网页中某些特殊数据进行检索,如标题或摘要等;在这种情况下,就有赖于数据分析管理子系统来萃取有用的信息了。能够有效率且精准的萃取有用的信息,意味着在用户查询时,会有更快速及更精准的查询结果。因此,全球信息网协盟(W3C)也在HTML中制定更多语意性汇总数据(Meta data),就是希望在萃取有用的信息时更有效率。
(3) 索引/查询子系统:
索引/查询子系统,乃是搜索引擎系统最重要的核心技术,它必须能够高效率的处理巨量的数据索引与执行强大的搜寻功能。
(4) WWW界面软件子系统:
WWW界面软件子系统,乃是一些界面程序,用来将搜索引擎与在网页整合。这个子系统最主要的功能是接受用户的查询需求及呈现查询结果。
对搜索引擎而言,索引/查询子系统还攸关着一个相当重要的议题,那就是查询结果的精准度。所谓「精准度」,我们可以用一个例子来说明,假设搜索引擎透过网络蜘蛛收集的网页中,只有1000个网页有出现「周蕙」这个词句。当用户查询「周蕙」时,如果搜索引擎能够把这1000个网页完整的找出来,那么这个搜索引擎的精准度是高的;若是搜索引擎无法完整地找到这1000个网页,或是把没出现「周蕙」的网页也找出来,则可以理解的是这一个搜索引擎的精准度是比较差的。
但是从更深一个层面来看,一个搜索引擎虽然能够完整地找到这1000个有出现「周蕙」网页,它的「精准度」仍然可能会受到用户的质疑。从经验上我们知道,当查询的输出结果太多时,对用户其实是不具任何正面意义的。因此,一个精准度高的搜索引擎,必须还要依据这1000个网页的重要性来进行排序(ranking)。有许多方法可以评估搜索引擎的好坏,而ranking的技术则是用户最容易感受到的一个评比项目。感受之深就好比在路上有人问您「荣总」在哪里?精准度高的搜索引擎会告诉他「台北荣总」、「台中荣总」或是 「高雄荣总」的网址,而不会先告诉他「台北荣总教学研究部」或「高雄荣总胸腔内科」的网址,如(图二)所示。
当然一个适合的ranking 算法,往往是相当复杂的。通常会以关键词所出现在网页的次数、与网页总字数的比例、出现的位置及被其他网页参考(reference)的多寡等因素来决定ranking 的权重,再予以排序。
搜索引擎的功能
常听人提到,在软件产业中必需发展没有文化区隔的软件,才会有进军国际市场的竞争力。扫毒软件就是一个很好的例子,事实上,全世界的计算机都可能受到同样病毒所感染;另外一个例子,大概就是搜索引擎了。我们知道有些国外开发的搜索引擎,面对华文数据(big5)的检索是有问题的;因此,对于国外的搜索引擎而言,这是一个进入障碍。然而,对国内厂商来说,却能轻易地检索英文或其他语系的数据。由此可见,国内的搜索引擎只要能提供完整的检索功能,将会有进入国际市场的优势。
在这个段落中,我们会从用户的观点来探讨搜索引擎应该具备的功能。
全球语文检索核心
可检索的内容不分语文种类,而不会有中文比较快,英文比较慢,或多种语系合并查询时产生谬误的现象(如查询「WWW网站」在某些中英文网页全文检索系统中会先转成「WWW*网站」的查询字符串,所以除了找到该找的网页外,还会找出同时包含「WWW」和「网站」的其它错误或不必要的网页。
中文同音功能
针对中文中同音近义字特别多的特性设计,能解决诸如「台湾」和「台湾」的同义词,或「意大利」及「意大利」的译名差异等问题,让用户能轻松找到该找到的数据。
全球语文容错功能
提供语文模糊容错功能,能判断依近似程度依序列出,例如输入「电子书」能查到「电子图书、电子百科全书」;又如我们想查「贝多芬」, 正确的单字应为「Beeth- oven」,如果输入「Beathoven」 或 「Beethaven」都能查到正确的「Beethoven」的信息。
多项目查询功能
让用户能同时输入几个有兴趣的关键词,并可要求某个关键词一定要或一定不要存在,而能进行方便且有效的查询。例如输入「+green, red, -blue」即代表查询数据中一定要有「green」,一定不能有「blue」,「red」则可有可无,但是如果有的话排序比分会比较高。
自然语言查询功能
让用户能输入口语化的问题,例如「主板的价格如何?」,系统会过滤出问题的重点再进行查询。
全球语文词组查询功能
让用户能以空白隔间数个字符串形成词组以进行近似该词组之内容的查询。例如用户可输入「apple pie」可查到含有「pie made of apple」的内容,输入「民雄 中正大学」可以找到含有「中正大学在民雄」的内容。
繁简中文对译
提供用户能输入繁(或简)体中文检索简(或繁)体中文内容,并以繁(或简)体中文显示网页结果。
此外, 搜索引擎也应该包括提除外字功能、同义字及布尔运算检索等功能。
搜索引擎在因特网的应用
对一个入门网站(portal site)经营者而言,必须思考许多重要的议题。例如如何吸引网络用户第一次光临这个网站?如何增加用户驻留网站的时间?如何让用户愿意重复上站,甚至每天上站?而搜索引擎在这一连串的思考过程中的确扮演一个重要的角色。当一个用户要寻找他想要的信息时,往往会想到利用入门网站的搜索引擎来帮忙,所以搜索引擎至少能帮助入门网站经营者达到吸引网络用户第一次上网及重复上站的目标。
在传统应用上,搜索引擎是入门网站必备的工具之一。所有入门网站几乎都会准备好搜索引擎「等待」用户来查询。然而这样的观念也在慢慢改变中,正如前面所提到的,搜索引擎的应用已不再是被动地等待用户查询,而是会主动地去寻找用户想要的信息。
在这方面的应用,有一个简单的例子,那就是个人化新闻。在某些网站中,用户可以自定义自己想要的网页信息,假设您希望每次上站都能看到有关于「张惠妹」的新闻,您只要完成订阅的程序后,就能在您每次登入(logon)这网站时,系统会立刻透过搜索引擎把所有当天有关「张惠妹」的新闻找出来,并显示在画面上。
另一个例子就是把个人化新闻跟电子邮件作整合。现在大多数的网络用户不见得每天会上哪个网站去看新闻,但却有每天收发电子邮件的习惯。假设有用户对「地震」的新闻有兴趣,可以肯定的是,他几乎没有办法完整的收集这些新闻;也不可能每天上入门网站或新闻网站来阅读所有新闻。这种情况下,就可以发挥搜索引擎的功效了。如(图三)用户只要到提供这些服务的网站订阅想收集的新闻关键词,就可以每天收到包含这些新闻的电子邮件了。
另外,搜索引擎还可以有不同的应用。例如您要购买某厂牌的A型号激光打印机,也许有很多网站都有出售这一产品,如果您希望买便宜一点的话,就必须到每个网站进行「比价」,以确保价格最低。如果把搜索引擎的技术运用进来,让网络蜘蛛去把这些网站的信息收集回来,然后再萃取这些会影响购买决策的信息,再针对这些信息加以编制索引就可以了。当用户输入「A型号激光打印机」,就可以看到这些网站出售A型号激光打印机的相关信息了,以快速决定向哪一个网站进行购买。
结语
因特网快速地累积信息,象征着这一波知识革命已在默默进行着。不论信息或是知识的数量,己经多到人类无法掌握的地步了,在追求速度与质量的今天,唯有用最有效率的时间及最好的工具,才能获得最有用的信息, 这也才是2000年后的竞争法则。本文仅就个人对搜索引擎粗浅的认识表达看法,事实上在无限的因特网空间中,还有许多很好的工具可以让我们来使用,也希望善用周遭的工具而达到掌控知识,驾驭知识的领域。
(作者任职于网擎信息软件公司)
(网际先锋2000.1月号68期)