随着电脑硬体及网路连线设备快速成长,网路上资讯量爆炸性的成长速度远超过硬体设备的进步。如何快速有效地收集所须资讯,并且加以组织整理,已经成为现代人不可或缺的能力。本文将带您一探搜寻引擎的基本运作原理,并经由分散式计算的架构来展望未来资讯搜寻的趋势。
搜寻引擎的前身
在网际网路(Internet)尚未建立的年代,图书馆早已成为人类知识与智慧累积的重要地点。除了平面媒体如:报纸、书籍、杂志、期刊等之外,想要在各种非数位媒体上搜寻资讯,不仅费时,而且并不容易找到所须的资料。
在1990年初Internet草创时期,World Wide Web(WWW,简称Web)尚未成型的年代,档案传输主要是透过 FTP(File Transfer Protocol)的方式来进行。如果想要分享档案,必须自行架设FTP伺服器,然后以口耳相传方式告知亲朋好友,该连线到哪个伺服器的哪个目录才能抓到什么档案。后来大量匿名式(Anonymous) FTP伺服器逐渐架设起来,使得所有使用者都可以任意储存或抓取各种档案,其中被用来搜寻这些档案的重要工具,就是Archie[1],这便是搜寻引擎(search engine)最早的起源。当时除了档案之外,还有储存在Gopher伺服器上的文件(只有纯文字,不含图片、声音、影像等多媒体)可供浏览,而Veronica[2]便是其中用来搜寻Gopher文件的一个系统。
资讯超载(Information Overload)
随着网际网路的蓬勃发展,Web已经逐渐整合各种数位媒体。在任何时刻,全球各地的使用者不断以网页(Web pages)的形式整理出自己所知的资讯,使得Web成为全球最丰富的动态知识库。
自从2000年以来,Peer-to-Peer(P2P,对等式)网路架构逐渐引起广泛重视。从Napster以MP3压缩格式进行音乐档案分享(file sharing)开始,到Gnutella、Morpheus,甚至是国内的ezPeer、Kuro等,各种档案分享软体充斥。这些P2P软体将网路上所有愿意分享出来的硬碟空间,整合成一个超大的网路硬碟,内容除了网页外,还包含了其他媒体格式,如:文字、图片、声音、影像、...等,更加丰富了网路上的资源。
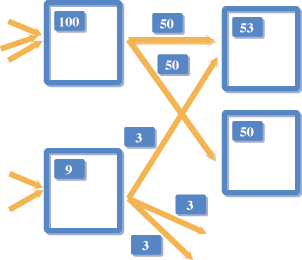
然而这些大量资料(data)如果不加以整理、消化,充其量只是一堆没有用的垃圾。因此如何在庞大且不断进化的网路资源中找到所想要的资讯(information),进而获得知识(knowledge)、甚至智慧(wisdom),已经成为非常重要的课题[8],如图一。
网路最佳工具 - 搜寻引擎
在这种资讯超载(information overload)的情形下,网页搜寻引擎(Web search engine,或简称搜寻引擎)应运而生。早期的搜寻引擎,如:Yahoo,是采用人工方式收集网页、整理资讯。他们以人工方式将全球的网页分为数类,每一类再细分更多的子类(sub-category),形成一个阶层式目录(hierarchical directory),以供查询。所有收集来的网页,则依照内容性质不同分别放在不同类别底下。
人工分类整理虽然比较精确,但是效率相当差,况且Web data 瞬息万变,Yahoo Directory无法即时反应出网页结构的动态变化,便可能产生许多过时、无法连结的dead link,也容易造成收录网页涵盖范围(coverage )有限的缺点。
因此,Lycos、Alta Vista等搜寻引擎开始运用电脑自动上网收集网页,并加以整理以供查询。之后,又有许多搜寻引擎纷纷以先进的技术,将搜寻结果由量的提升进一步迈向质的追求,从此搜寻引擎进入一个新的纪元。
搜寻引擎如何运作?
如图二所示,搜寻引擎大致可分为两个部分:一个是Web Crawler(或robot, spider),另一个是检索界面(Query Interface)。通常大部分搜寻引擎是利用Crawler程式,将Web上的网页,尽可能的抓下来 (crawling),并快取(cache)在伺服器上。然后根据网页内容所出现的重要关键词(keyword)建立一个索引 (index),以便日后能快速搜寻到使用者所想要的资料。当使用者透过检索界面发出一个检索(query)时,搜寻引擎便能查询到检索字词(query term)相关的网页,并将结果传回给使用者。
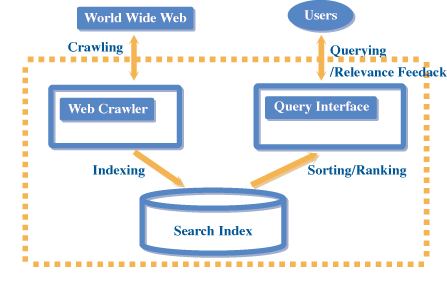
| 《图二 Search Engine 的架构示意图》 |
|
查询结果
通常检索越短、越模糊,找到的结果会比较多,但是可能其中包含不少杂讯(noise),并非我们所要的资讯;相反地检索越明确,找到的结果会比较少,也比较精准,但有些时候涵盖范围(coverage)可能不足,无法提供足够相关资讯。因此如何缩短使用者和搜寻引擎间语意上的隔阂(semantic gap),成了改善搜寻品质一个很重要的关键。
如果符合检索条件的结果数量太多,使用者可能很难从中找出想要的,为了能更快速方便地挑出重要资料,通常会将结果依照重要性顺序(relevance ranking)排序(sorting)。例如在Google中使用的是 PageRank[4]技术,利用网页中链结结构的分析(link structure analysis),可以决定出各网页的重要性分数,如图三。
基本想法很简单,一个网页如果被连结(link)越多次,表示该网页较重要(authoritative);而一个网页的重要性又会随着里面包含的连结传播(propagate)出去。套用这样的递回(recursive)关系不断计算下去,便可以算出每个网页的重要性分数。事实上除了PageRank之外,其他人也提过类似的链结分析方法,例如Kleinberg的Hub-Authority[5]观念,目的都是为了增进搜寻结果的品质。
常见的搜寻引擎
除了Google之外,目前常见的搜寻引擎有:Yahoo、Lycos、Alta Vista、Northern Light 等。每一个搜寻引擎所收集的网页不同,索引方式也不同,因此同样的检索传回的网页及顺序也不尽相同。通常依照搜寻的目的不同,我们会建议使用不同的搜寻引擎[6]。
另外,由于个别搜寻引擎的差异,使用者可能想要结合不同搜寻引擎的特性,弥补涵盖率不足或品质不佳的状况,以更快找到更多符合需求的资料。因此,有所谓的meta-search。也就是将一个检索分别向数个搜寻引擎查询,然后将各个结果分别列出或做某种结合。常见的meta search engine有很多,例如:Ixquick、Excite、Dogpile ... 等。
从集中式到分散式搜寻
搜寻所包含的抓取(crawling)、索引(indexing)、排序(sorting)等动作相当费时,而且须定期执行。如果单靠一个集中式搜寻引擎,要同时服务全球大量的检索,不但效率差,而且扩充性(scalability)也不好,同时能服务的用户端数量很有限。
因此想要增进搜寻效率,必须将负担(load)分散出去。例如在全球各地设置备份伺服器(replica server),并且将各地的检索依照其所在区域,分别重导(redirect)至相对应区域的伺服器,则服务效率会比较好,但是扩充性恐怕还是一大问题,因为如何布署(deploy)众多的电脑在全球各地,对于主机控管、维护、以及安全性都是极大的挑战。
分散式搜寻与P2P
于是分散式搜寻(distributed search)的主要想法是将crawling、indexing及sorting等动作分散(distribute)到各个自愿参与的(volunteer)主机上执行,如此,负担不会集中在一个伺服器上,而是平均分摊到各个主机上,搜寻效率可再提升。同时藉由分散式计算扩充性佳的特性,使得搜寻工作变得更稳定(robust)。
最近三年来除了Web 之外,P2P网路成了另一个热门的储存媒体。一般而言,P2P网路依其架构可分为集中式(centralized)、纯P2P与混合式(hybrid) P2P网路。例如 Napster采用的是集中式架构,所有的使用者及档案传输都要经由集中的伺服器来管理。而Gnutella则是纯粹P2P,也就是说所有主机地位完全均等,没有任何一台主伺服器。 Morpheus则是介于两者的混合式架构,即每个区域有super-peer,集中负责该区域主机的管理;但是super-peer之间则仍是纯粹P2P。
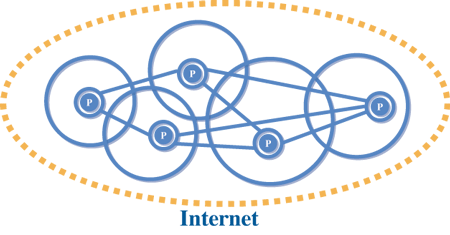
P2P网路架构主要的好处是开放(open)、扩充性(scalability)、匿名(anonymous)与容错(fault tolerance)。开放式架构有助于资料的分享,扩充性可以同时服务很多人,不致影响系统效能,匿名可确保使用者身份的隐私,而容错则可让任何人随时加入或离开P2P网路,不会对整体产生太大的影响。请参考图四。
一般在集中式P2P网路中,比较容易搜寻,因为每个peer都要登入伺服器,因此与传统Web搜寻没有太大差异。所以,目前常见的分散式搜寻引擎大多为Gnutella-based纯粹P2P的架构,例如 InfraSearch、Grub、...等。
另外,一般P2P client也大多含有搜寻档名的基本功能,因为纯P2P网路并无法确认每个peer储存有哪些档案,必须依赖搜寻功能。但由于目前储存在P2P网路的档案并没有一个很好的方法来确认其真实性(authenticity),只能根据档名(filename)来做索引。至于一个档案是否为合法授权(authority),或是内容与档名是否名符其实,目前只能靠投票(voting)这类的机制让使用者来评分。如果能在分享档案时加入签章(signature),而使用者能在取得档案时做验证(authentication)的动作,或许更能够确保P2P档案的合法性与内容的正确性。
另外,各地主机通常会存有当地常被查询的资料。基于这种区域性(locality)的特性,透过各地主机的合作,有机会找出更多的资料。由于传统搜寻引擎仅止于网页的搜寻,因此如果能将搜寻范围扩展到P2P网路上所分享的档案,其资料涵盖的范围更广,所能收集到的人类知识也能更广。
但是,这种作法有个缺点,因为纯P2P广播(broadcasting)的关系,每个 peer地位相当,同时是client也是 server。因此所有检索都有可能流经许多peer才到达使用者,效率有待考验。一般解决方法是采用cache来增进效率,同时又可增进区域性档案存取效率。
如前言所述,资料(data)并不是知识(knowledge),它必须经由整理成为资讯(information),再经由适当的理解才可能成为知识(knowledge),因此越大量的资料就须要更快更好的处理。此外网路上资料的品质有待验证,尤其是P2P网路上的资料,如果连最基本的资料真实性(authenticity)都无法确认,就更不用提要在其中撷取出什么有用的资讯(information)了,因为根本不知道里面包含的内容是什么。
展望未来
未来的搜寻引擎会是什么样子呢?应该要能做到:速度快(fast)、够聪明(smart)、符合每个人的需求(personalized),而且要好看、易用(user-friendly)。
首先,速度是使用者对搜寻引擎最直接的感觉。除了资讯撷取(information retrieval)技术不断再提升之外,P2P网路也许是另一个有待突破的领域。其次,由于每个人兴趣不同,资讯需求也不同,因此搜寻引擎必须要能根据每个人的使用习惯加以学习、调整(adapt),才能更贴近使用者的需求。另外,使用者界面更是使用者直接面对的部分,如何在人机介面上做到易用(user-friendly),是必备的条件。
最后,电脑够聪明,才能理解人们所须要的是什么,这是所有电脑系统都想达成的目标。通常使用者很难用搜寻引擎查询到想要的资料,大多是因为不知道如何发出比较精确的关键词给搜寻引擎。因此未来的搜寻引擎要能够帮助使用者清楚地发出一个查询概念(concept),并且列出相关概念及资讯,并导引使用者点选,逐步修正找出想要的精确查询。当然要达到这目标,还需要整合许多资讯撷取(information retrieval)及自然语言处理(NLP)中语法(syntax)与语意(semantic)的相关技术。
事实上,网页探勘(Web Mining)已经成为目前学术研究中最重要的课题之一。因为Web所蕴藏的无数资源还在不断成长,如果再加上P2P网路所能提供的资料更是惊人。因此,逐渐地搜寻将不再只是关键词比对或是全文检索而已。更重要的是,如何从这些资料撷取出有用的资讯。许多人类认为理所当然的概念(concept),在电脑中却是困难重重。资讯抽取(Information Extraction)只不过是网页探勘的第一步。抽取出的资讯还须要透过某种程度的理解(reasoning)的过程,才有可能进一步自动整理出像人事时地物等meta-data,然后才能谈到真正的知识,这些都还有待进一步研究探讨。
(作者为中研院资讯科学所博士后研究员:jhwang@iis.sinica.edu.tw)
表一 本文相关组织与网站连结


![《图一 从数据、信息、知识到智能 [3]》](/art/2003/11/261648157673/p1.gif)