製藥公司藉由執行嚴格的測試來衡量所生產藥物的關鍵性品質屬性。當特定批次的產品出現問題時,製造團隊必須盡快找出根本原因,以避免造成交貨延遲和關鍵藥物的短缺。
由於各式各樣的原始資料、生產機台、以及藥品製程當中的多項處理步驟,要執行準確且及時的根本原因分析(root case analysis)具有高度的挑戰性。在從前,團隊會將原始材料的標籤和從機器印出的紙本資料手動輸入到工作表進行分析,不過這種方法需要花費很多的時間,而且容易出錯。除此之外,當時還沒有可以一口氣分析如此龐大資料集的工具及方法。
在Cipla,我們的團隊使用一個網路應用程式(app)來進行先進的製程解析。這個使用MATLAB建立的app可以自動收集資料、使用機器學習模型來分析資料、並且將結果視覺化呈現出來(圖1)。
| 圖1 : Cipla透過在MATLAB建立的app執行藥物製造分析 |
|
以前需要耗費幾個星期來找出根本原因,有了這個app之後,只需要幾天就可以完成。而且我們可以預測特定批次的潛在問題並立即採取修正措施,而不是等待長達14天,收到成品品質控制測試結果後才進行處理。
資料的收集和前處理
藥物製造團隊需要分析的資料高度異質(heterogeneous),資料來源也不全相同,不過這些資料大致上可以區分為兩大類別:關鍵材料屬性(critical material attributes;CMAs)和關鍵流程參數(critical process parameters;CPPs)。
CMAs包含製程中使用的原始材料特性,像是材料的密度和實際的尺寸失真,以及材料的供應商、年份和保存期限。通常一項產品會由大約20種原始材料組成,每一種材料包含至少十幾個CMAs。CPPs則包括在製造過程之中多個單元操作捕捉到的時間序列量測值。
舉例來說,要完成一個單一單元操作如流動床造粒(fluidized bed granulation),可能會花上2至3個小時,或者更久。在這段期間,每分鐘記錄一次溫度、濕度、和空氣在機器流動的速度和濾波器的壓差等流程參數。其他單元操作,像是冷凍乾燥(lyophilization or freeze-drying)通常需要48小時或更長的時間來完成。
我們向MathWorks Consulting尋求協助,開發一個應用程式來收集並建構這些資料。使用Database Toolbox(資料庫連結工具箱)從Microsoft Azure資料倉儲(data warehouse)和其他的資料庫檢索CMAs和批次資料。透過Industrial Communication Toolbox (工業通訊工具箱),可以直接從設備中的OPC伺服器存取額外的CPP資料。Database Explorer app對於Cipla資料庫的連接和視覺化的資料探索特別有幫助。
我們存取的CMA資料相對乾淨,因此需要的前處理並不多。針對CPP資料,特別是壓差的量測值的雜訊就比較多。我們使用Signal Processing Toolbox(訊號處理工具箱)中的濾波器來降低雜訊,並且發掘資料之中的趨勢。
建立機器學習模型
當有了結構完善的CMA和CPP資料代表物,下一個任務是要建立機器學習模型。這些模型讓我們可以決定哪一些材料特性和流程參數會對特定的屬性產生最大的影響。
以數學的角度來說,可設一組函式y=f(x1,x2,…,xn),其中y為關鍵品質屬性,每一個x則代表一個CMA或CPP變量。我們需要一個模型來協助判斷每一個x各對y產生多大的影響。
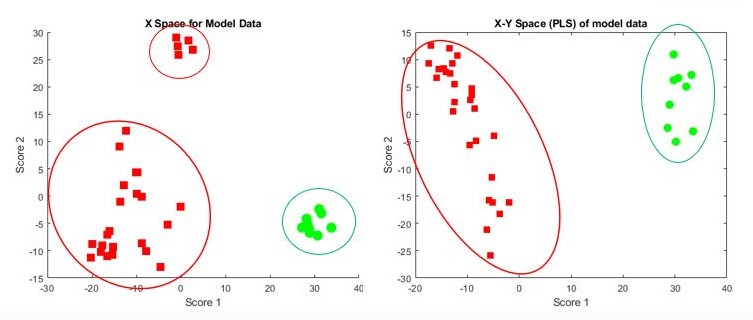
我們實現了一個演算法,它接連運用了三種機器學習技巧:主成分分析(principal component analysis;PCA)、偏最小平方(partial least squares;PLS)、以及隨機森林(random forest)。X-space(PCA圖表)可看出不同批次的原材料屬性確實存在差異且/或處理方式有所不同(圖2)。
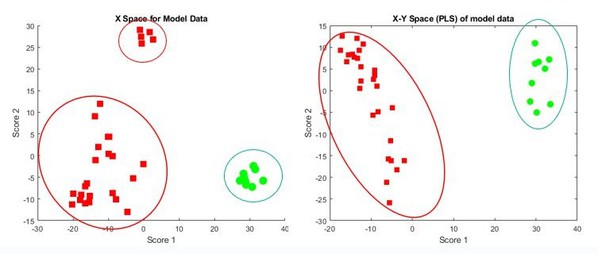
| 圖2 : PCA(左)和PLS(右)結果。綠色圓點為具有效力的批次;紅色方點為脫靶批次。(source:Cipla) |
|
此外,即使使用多種方式對具有效力(on-target)和脫靶(off-target)的批次進行處理,都還是生產出脫靶的產品。我們使用x-y space(PLS圖表)來確認此情況。在這張x-y space圖表,所有的脫靶群體聚集在一起形成了一個大型的脫靶區域。我們對最高的PLS採用隨機森林來了解模型將各批次分類為具效力和脫靶的準確程度。使用變量和隱性變量(latent variables)的權重(weightage)有助於更進一步地了解該批次為具有效力或脫靶的原因。
我們選擇機器學習而不是深度學習,因此可以達成分析之中的一項關鍵要求:可解釋性。我們必須完全了解所有被辨識出來的製造問題,才能夠對它們進行全面性的處理,並且避免未來再次發生這類問題。傳統的機器學習能夠支援這種程度的理解力,而深度學習通常無法做到。
Web App的打包與部署
我們另外一項重要目標是要達成解析民主化(democratization of analytics):我們希望開發的解決方案能夠讓Cipla的諸多使用者都有辦法使用,而不是只侷限於一小群專家。
為了達到這項目標,我們透過App Designer建立一個簡單的介面,並將機器學習演算法打包進入此介面,並且透過Web App Server(MATLAB網路應用程式伺服器)來將打包後的演算法部署為網路應用程式(web app)。
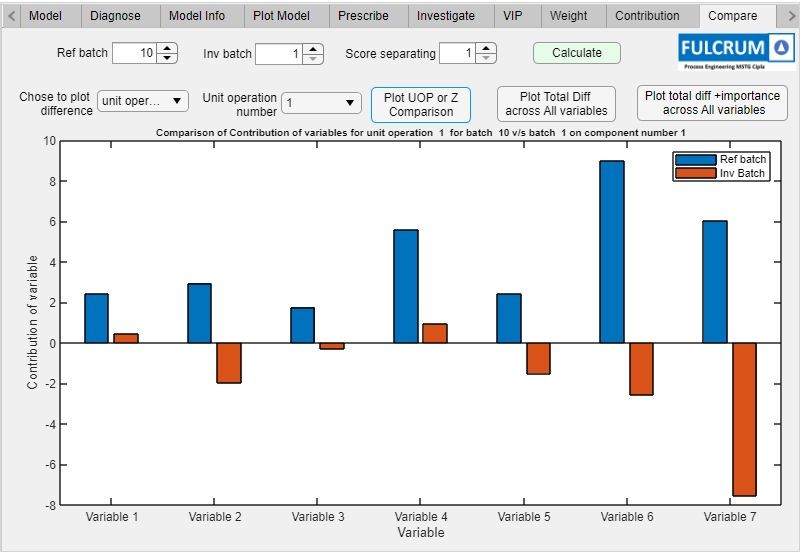
使用者在操作這個app時,一開始會先選擇他們想要分析的產品。這個App接著檢索該特定產品的CMA資料,並且建立PCA、PLS、和隨機森林模型。App從模型展示結果,包含每一個變量對於關鍵品質屬性所相關的作用,並強調重要的因素(圖3)。
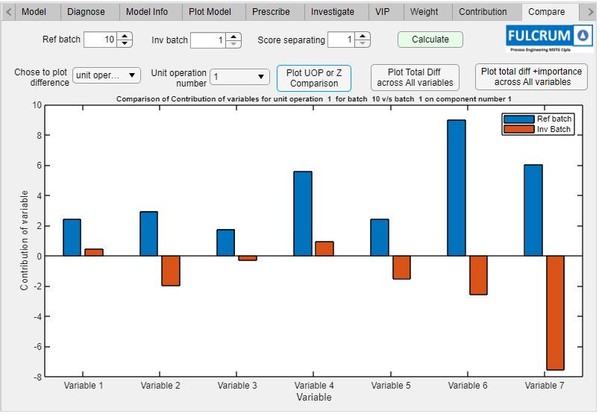
| 圖3 : 從CMA資料模型取得的結果,包含每一個變量關聯的作用。 |
|
在查看結果之後,使用者可以決定要不要建立一個包含這些重要因素的縮小版模型來改善模型的準確性。舉例來說,如果初始的迭代包含500個變量,但是其中一個含有300個變量的子集,看起來對結果只有些微影響,接下來,使用者便可以省略該子集來簡化模型,並且重新執行分析。
即時版本App的試行
我們團隊現在正在開發這個應用程式的即時版本,而且打算在今年開始試行。這個版本即時地捕捉了來自單元操作的OPC伺服器資料,將資料加入機器學習模型,再判斷這樣的流程是否運作於建立的控制參數內。
為什麼選擇MATLAB?
在決定使用MATLAB來進行製造分析之前,我們考慮過幾種替代方案,其中一個評估的選項是商業套裝軟體。這個軟體非常昂貴,有一部分原因是它是針對醫藥產業量身訂製,而我們無法完整對它依照需求客製。
另一個選項是使用Python或其他類似語言的開源函式庫開發自己的解決方案。不過這個選項並不可行,因為我們必須確保使用來建立app的演算法通過徹底的檢驗和測試。我們也需要技術支援來協助存取來自各種組合的資料庫資料。有了MATLAB和MathWorks顧問服務(Consulting Services)的支援,我們可以建立一個完全客製化、低成本的應用程式,並且分享至公司內部各個需要的地方。
(本文由鈦思科技提供;作者Ram Kumar、Akshay Hatewar、Vaidehi Soman於Cipla製造科技集團)