今日的嵌入式多媒体应用方案包括更多与系统控制( MCU的典型角色),和信号处理 (通常是DSP的职责)之间的交互关系。如今也有内嵌式嵌入式媒体处理器可以处理MCU和DSP的作业,而过去非常熟悉MCU应用模型的C语言程序设计师也正在转换到新的领域,程序代码和数据流的智能管理能够使系统性能大幅改善。对MCU程序设计者而言,可以采取「放手(hands-off)」的方法和使用简单的指令与快取来管理数据流具有很大的吸引力。不过我们仍旧需要考虑媒体处理器的高性能直接内存访问(direct memory access;DMA)能力。
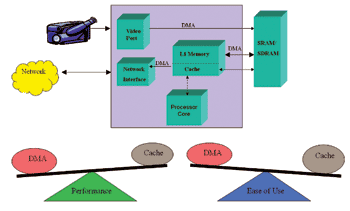
(图一)表示在典型的多媒体应用中,选择快取取忆体或DMA所必须作的一些取舍。本文的目的在突显并分析了解出这些冲突点,进而能对系统开发作更佳的调适。
<图注:图1:嵌入式媒体处理器的概览该图表示L1内存与更大的外部内存之间的多重路径。由外部储存的程序代码与数据可以在L1中被快取到,或者区块可被移至L1内存,当做是一种经由DMA控制器的独立背景处理。传送接收大型数据缓冲器的周边可直接对它们进行直接内存访问(DMA)给外部内存,而不用涉及到处理流程中的L1内存。>
内存架构-管理需求
多数具有层级式内存架构的媒体处理器都会在许多不同大小,和性能等级的内存间努力取得平衡。最靠近核心处理器的内存(经常叫「第一层」或「L1」内存)往往以全频率运作,而且通常能在一个周期(cycle)中执行指令。L1内存经常再分割成指令和数据区,以有效利用内存总线带宽。此内存通常)可设定为SRAM或快取。最需要决定性(determinism)的应用程序可以在一个核心频率周期存取芯片内建(on-chip)的SRAM。对于需要较大程序代码的系统,亦可以运用额外的芯片内建和外部(off-chip)内存,不过会增加延迟时间(latency)。
层级架构就本身来说只是普通适用;现在的高速处理器会迁就于只能在较慢的外部内存运作的大型应用程序,因而调慢作业速度。程序设计者可以选择手动将重要的程序代码移进和移出内部SRAM,以增进效能。另外,在架构中增添数据和指令快取也可使外部内存更易管理。高速缓存减少手动将指令和数据移动到处理器核心的次数,因而大幅简化程序模型。
指令内存管理-使用快取或是DMA?
对于内嵌式嵌入式媒体处理器市场作一快速检视后可以发现,核心处理器的速度都在600 MHz或更快。虽然这样的性能开启了更多新应用的可能性,其最高速度仅能在以内部L1内存执行程序代码的时候才能展现。当然在理想上内嵌式嵌入式处理器会有无限的L1内存,可是这并不实际。所以程序设计者必须考虑数种方式以利用处理器现存的L1内存,并对其系统作内存和数据流的优化设计。现在来看几种情况。
首先而且最直接的情形是,当目标应用程序完全可以在L1指令内存内执行。在此情况下除了程序设计师直接将应用程序代码映像(map)到内存空间,并不需要任何特别的动作。而媒体处理器也很自然地必须在要架构层级上,有更佳优秀的程序代码密度性能。
第二个情况是 程序设计者采用快取(Cache)机制,存取容量较大且较便宜的外部内存。高速缓存会自动将所需要的程序代码加载L1指令内存。这个过程的重要优点在于程序设计者不用管理程序代码进出快取的动作。此法在程序代码是以线性方式执行时最为适合。对非线性的程序代码来讲,快取线(cache-line)可能会因更换太过频繁而无法改善效能。
指令高速缓存实际上扮演两个角色。其一是帮助指令从外部内存以更有效的方式预先取得。这就是说当发生快取遗漏(cache miss)时,快取线回填(cache-line fill)会取得所需要的指令,以及其他快取线所包含的指令。如此可确定当第一笔指令被执行时,紧接在后的指令也已经取得了。另外既然高速缓存通常是以取代「最久前使用过」内存位置的演算方式运作,最常执行的指令往往都保留在快取中。这也是好处之一,因为在L1快取中的指令能够像在L1 SRAM一般,在单一核心周期周期中执行。也就是说,假使一段程序代码已经被读取过而且尚未被替换,这个指令就已经准备好下一次的执行动作。
大多数严格追求时效性实时性的程序设计师,比较不信任使用高速缓存可达成系统的最高效能。他们的论点是如果正好需要执行一组不在快取的指令时,效能反而会降低。利用快取锁定(cache-locking)的机制正可以弥补这个缺点。一旦重要的指令加载高速缓存后,可以锁住快取线使指令不被替换掉。程序设计者因此能够将需要的指令留在高速缓存内,而让快取机制管理较不重要的指令。
最后一种情形是使用独立于处理器核心的DMA信道,可将程序代码从L1内存中搬进搬出。当核心运作于内存的某一区段时,DMA会带入下一个被执行的区段。这种机制一般称为重迭(overlay)技术。
虽然经由DMA将指令重迭进L1指令内存比起加载快取提供更多的决定性,这却需要程序设计师投入较多的心力来完成。换句话说,程序设计者必须安排一个重迭的策略,以及适当设定DMA信道。不过一个妥善规划的方法所换取的性能提升还是很值得的。
数据存储器管理
内嵌式嵌入式媒体处理器的数据存储器架构对整体系统性能就像是指令频率速度一样地重要。由于在多媒体应用中经常会有多笔数据传输同时发生,总线结构必须要能支持核心和DMA存取内部及外部内存的各个区域。能够自动仲裁DMA控制器和核心是很重要的,否则性能会大幅减低。仅有在设定DMA控制器后才需要核心-DMA的互动,然后当数据准备被处理时会对中断产生反应。
数据撷取通常是处理器的基本功能之一。虽然将数据传进或传出外部内存一般而言是最没有效率的机制,它却是最容易的程序模型。小型快速写入的内存有时候可当作是L1数据存储器的一部份,但是如果核心必须从外部内存读取全部的数据,则对较大的外建缓冲区之访问时间将会受到很大的影响。这不仅是需要多个频率周期以撷取数据,而且核心也会一直在忙着处理这些任务。
考虑如何让核心处理器有效处理读写动作是一个重要的课题。有效率的媒体处理器会有多槽位的写入缓冲区,可以在所有加载的写入动作完成前让核心处理接下来的指令。以下面的程序代码为例,假使P0指向一组外部内存地址而P1指到一组内部存储器地址,第50行指令将会在R0 ((从 第46行起))被写入外部内存之前就被执行:
…Line 45: R0 =R1+R2;
Line 46: [P0] = R0; // Write the value contained in R0 to slower external memory
Line 47: R3 = 0x0;
Line 48: R4 = 0x0;
Line 49: R5 = 0x0;
Line 50: [P1] = R0; // Write the value contained in R0 to faster internal memory
在多媒体应用和其他数据密集的作业里,将大笔的储存数据经常移进移出SDRAM有其难度。因为靠核心撷取数据一定会花一些时间,大量的传输必须仰赖DMA或是快取以维持系统效能。
使用DMA作数据管理
想要在多媒体系统中有效使用DMA,就必须要有足够的DMA信道来完全地支持处理器的周边外围装置以及多组内存DMA串流。明白这一点是很重要的,因为一定会有原始的媒体串流进入外部内存(经由高速外围装置),同时数据区块会在外部和L1内存来回移动供核心处理。还有DMA引擎可以让数据直接在外围和外部内存间传输,不用「中途停留」在L1内存,这可以节省密集演算中许多额外的数据传递。
随着数据速率和性能的需求提升时,设计者对其配置的「系统性能调节」控制也变得愈发重要。举例而言,DMA控制器或许可以调整作为在每一频率周期传输一个数据字符。当同方向有多笔传输在进行时(例如全部从内部存储器移到外部),这通常会是操作控制器最有效的方式,因为可避免DMA总线产生空闲时间。
不过万一双向都有多笔影音串流时,「突发(burst)控制」便是避免一笔串流占用整个总线的必要手段。比方说,如果DMA控制器总是开放DMA总线给准备传输数据字符的外围,那么在连接到SDRAM时整体输出量会因而降级。在几乎每一频率周期都改变数据传输方向的情形时,SDRAM总线的转向延迟会大幅降低输出量。因此具有可程序化信道突发容量的DMA控制器,会比其他只有固定传输带宽的控制器有着明显的优势。由于每一DMA信道都可以链接外围装置到内部或外部内存,因此可以自动对外围装置提供紧急总线的链接服务也是很重要的。
另外一个功能,二维(2 D)DMA,可以提供多个系统层级的优点。其一是可以让数据在内存内以比较直观的处理次序置放。例如(图二)所示,luma /chroma或RGB数据可能会以序列的方式由影像传感器传来,但是能够自动储存在不同的内存缓冲区中。2D DMA的交错/反交错(interleaving/deinterleaving)功能省下了在处理视讯和影像数据前,内存总线的额外作业。二维DMA的选择性传输功能亦可使系统的数据带宽最小化,例如只传送想要的输入影像区域,而不用传整个影像。
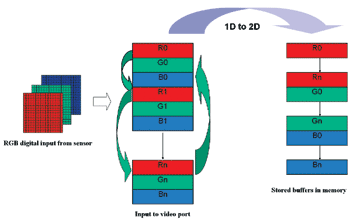
| 《图二 2D DMA功能可立即将数据分离成缓冲器》 |
|
其他重要的DMA功能包括排列DMA信道的优先等级以符合现有的周边任务需要,同时可设定相对应的DMA中断以配合优先等级。这些功能有助于确保数据缓冲不会因为DMA对其他外围的活动而产生溢流(overflow),而程序设计师也有额外的自由度可以基于每一DMA信道的数据交通进行系统的整体优化。
因为内部存储器一般都是以次记忆库(sub-bank)的方式构筑,只要将数据放在不同的记忆库中,就能在一个频率周期中同时让DMA控制器和核心存取。举例说明,核心可以在一个次记忆库中运作,而DMA则在第二个次记忆库中占占了一个新的缓冲区。在某些情况下同时存取同一个次记忆库也是有可能的。当存取外部内存时,通常只有一组实体总线在同步与异步内存之间进行多任务作业。
关于数据快取
现在DMA控制器所具备的弹性可说是一把双面刃。当一个大型的C/C++应用程序在处理器之间移植时,程序设计者有时候会犹豫是否要将DMA功能整合进已经可作业的程序代码。这里就是数据高速缓存派上用场的时候。通常数据快取会将数据带入L1内存作最快的处理。数据快取之所以吸引人是因为其动作类似迷你DMA,但不需要花程序设计者太多的心力去设计。
由于典型快取回填的特性,数据快取最有用的时候是处理器作业于外部内存的连续数据位置时。这是因为快取不只是储存现在处理中的实时数据,它甚至会预先撷取邻近区域的数据。换句话说,快取机制假设现有的数据字符有很大的机会是将被处理的邻近数据区块的一部份。这个猜测对多媒体串流应用是很合理的。
既然数据缓冲通常源自于外部外围装置,以数据快取作业并不总像指令快取那样容易。原因是必须要用手动的方式来维持非「窥探性」高速缓存的一致性。对这些高速缓存而言,必须要在尝试存取新数据之前使数据缓冲失效。在以C为基础的应用程序内涵中,这种数据是属于「挥发性的」。
在一般的情形中,当存在快取中的变量值不同于来源内存时,这表示快取线可能已经「脏了」而仍然必须写回内存。这个观念并不适用于挥发性数据。反而在这种情形快取线或许是「干净的」,但是来源内存己经改变而核心处理器并不知道。此情况中,在核心能够安全存取数据快取中的一笔挥发性变量前,必须要先让影响到的快取线失去效用((但不是冲刷!))。有两种方法可以达到此目的。快取可以被直接写入,或者执行一个「使快取失效」的指令让目标内存地址失效。直接法通常比较繁琐,但是两种方法是可以交互使用的。然而当有大型数据缓冲时((例如一个大于数据快取的容量)),直接法通常是较好的选择。失效指令永远较适合于缓冲区容量小于快取容量的情况。这在即使需要循环((loop))仍然成立,因为失效指令通常是随着每一个快取线的大小增加,而不是一般在正常地址模式的1、2、或4位增幅。
另一个重点是订定挥发性变量,不管是否被放入高速缓存。如果同时被核心处理器和DMA控制器所共享,则程序设计师必须要启用某些安全作业的信号。总结来说,最好将挥发性数据跟数据快取撇清关系。
选择DMA或快取的系统导引
接着将参考让我们看看三种广泛使用的系统配置,以探究那一种方法最适合于某种系统分类。
指令快取,数据DMA
这大概是最多人使用的系统模型,因为媒体处理器的架构经常就是这个样子。假如应用程序负担得起,将程序代码存入快取中能够减缓指令流管理的复杂度。这适用于系统并不需要很强的实时性时,所以一个快取遗漏并不会造成紧临事件(例如,视讯更新或是音频/视讯同步化)时效性太大的灾难。
此外,当处理器性能远超过其处理需求时,快取机制一般而言是比较安全的方式,因为快取遗漏比较不会产生传输瓶颈。虽然在实务上可能不常使用「功能过强」的处理器,不过我们依然可用能译码和播放压缩影音的可携式媒体播放器为例作说明。在放音模式的性能需求仅会是播放视讯时的数分之一。因此每种模式的指令/数据管理机制有可能会不同。
经由DMA管理数据是多数多媒体应用的第一选择,因为这通常牵涉到操纵大量的压缩及未压缩视讯、图形和音频缓冲。除非数据是在准稳定的状态(例如屏幕上的固定图标),否则将缓冲数据存入快取是没有什么意义的。还有如上文中所之前的讨论的,通常会有同时多笔数据缓冲传输进出核心处理器的情形,未处理的区块要被调整,部份调整过的区段准备移到暂存区,而完全处理完的区段则被送往外部显示或储存组件。DMA是这些缓冲的逻辑管理工具,因为它允许核心处理器不必担心如何搬运就能够作业。
指令快取,数据DMA/快取
这个方法跟上一个类似,除了部份的L1数据存储器被区分成快取,而其余的SRAM可以当成DMA用。此架构在处理关于大量静态系数或查询表的算法时非常有用。举例来说,存入一个正弦/余弦表到数据快取可帮助快速地计算FFT。量化表可以存入快取以加速JPEG编译码则是另一个例子。只不过这个方法有其限制,当应用程序得以在一个频率内存取常用的常数和表格时,也放弃了等量的数据SRAM,因而限制了让一个频率存取数据可用的缓冲大小。评估这个交换条件的有用方法是在一个统计图表(许多开发工具套件有提供)上尝试不同的情境(数据 DMA/快取 vs仅有DMA), 以评断各个环境下花在程序代码区块的时间百分比。
指令DMA,数据DMA
这种情形的数据和程序代码之间的依存关系十分紧密,所以开发人员必须要手动设定指令和数据区段搬移进出芯片的时程。在这种需要强调强时效性实时性的系统中决定性是必要的,所以快取并不适合。
虽然这个方法需要较多的规划,其结果成果是一个需要执行的程序代码永远比数据先出现,而且缓冲溢流也不会遗漏数据区块的决定性系统。因为DMA流程可以同时串连而不须核心作业,可以保证新流程开始时上一个已经完成,所以数据或程序代码的移动也保证是达成的。这是同步数据和指令区块最有效的方法。
指令/数据DMA的组合尚有一个值得一提的理由。它提供了一个在仿真和除错期间测试系统编码和数据流的便利办法,因为这个时候一般无法直接存取快取。程序设计者可以调整或强调系统配置的「问题点」。
系统会需要指令和数据DMA的一个范例是视讯编码器/译码器。视讯与其相关音频需要是决定性的以满足用户经验。如果DMA在每一次完整缓冲转移后都发出中断讯号给核心,可能会造成系统明显的延迟,因为中断需要与其他事件争夺优先级。还有在中断服务的头尾内容转换固定需要好几个核心处理器周期。这些因素加起来都会影响为了保持系统是否为决定性的首要目标。
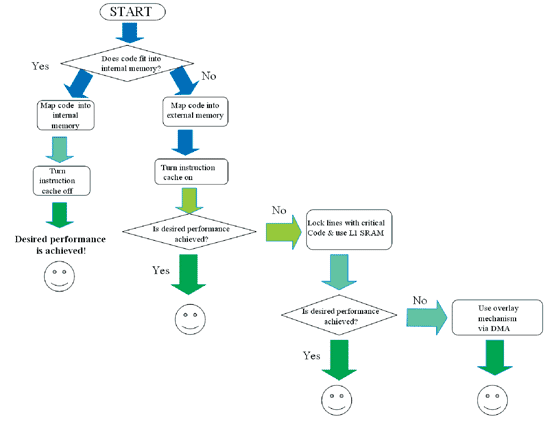
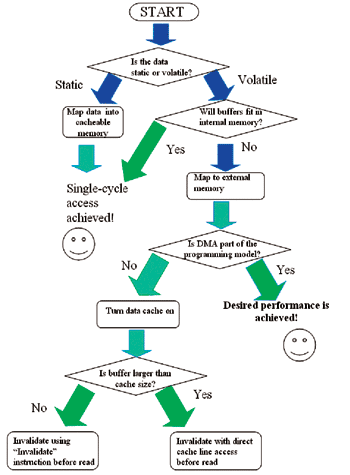
(图三)和(图四) 为综合以上的讨论,所提供的快取或DMA选择导览。
结语
数据快取vs.DMA决定流程
简而言之,并没有一个单一的答案来说明高速缓存和DMA何者才应该是多媒体系统中程序代码和数据传输的最佳选择。然而一旦开发人员意识到其中的各擅胜场,就可以到达一个「中间地带」作为系统的最佳状态。
[2] D.A. Smolyansky, Time Domain Network Analysis:Getting S-parameters from TDR/T Measurements - Infiniband PlugFest, 2004> |
|
|
 |