近年来手持式行动装置快速成长。大量的音乐/视讯播放与影像处里等多媒体应用被整合进诸如手机,个人数位助理(PDA)与手持式多媒体播放器(PMP)。除此之外,光采炫目的绘图人机介面(GUI)以及三维绘图游戏更是被视为促使手持式行动装置下一波的成长动力来源。不容置疑,会有越来越多的针对各种标准的音频/视讯标准的硬体加速器以及绘图处理器被嵌入在手持式行动装置平台上。到目前为止,已经有许多低功率绘图处理器的发表[1][2][3]。从系统的角度来看,如果能将视讯加速器与绘图处理器加以整合不但能增加硬体利用率,减少晶片面积降低成本更能减低消耗功率,这对于下一代多媒体手持式行动装置是个非常重要的因素。
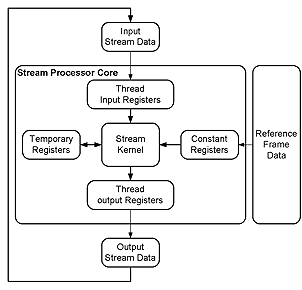
虽然视讯与三维绘图应用在资料结构与运算型态上有许多的不同,但以资料串流模型(Data streaming model)[5]来看其实是非常相似。因此我们提出资料串流模型(Stream processing model)的多媒体串流处理器架构来处理视讯与三维绘图运算。串流处理模型如(图一)所示。此处理器亦为第一篇被记载单一架构能同时支援三维顶点处理运算(Vertex Shader Model 3.0)[4]及视讯压缩功能的低功率晶片。在此创新的架构中提出了三项创新的技术,来达到最低功率与最高的硬体利用率以及最高的处理速度。分别为可调适性多执行绪技术(Adaptive Multi-Thread, AMT),可重组式记忆体阵列架构(Configurable Memory Array, CMA),与几何转换后滤除模组(Early Reject After Transform, ERAT)。最终此处理器能达到三维绘图中12.5百万顶点输出及使用完全寻找移动估计演算法(Full search motion estimation)可达到每秒三十张CIF解析度(352x288)的视讯压缩。
串流处理器架构
(图二)所示为串流处理器核心架构。此核心为双执行槽超长指令集架构(Two-issued slots VLIW)并采用单一指令执行多重资料流(SIMD)指令。当两个指令槽(Slot)同时执行,每个指令槽执行四个通道的浮点运算,将可达到每秒四亿个浮点运算(400MFOPS)。在针对视讯压缩处理指令[7]的定点运算下,更可以达到每秒八亿个定点运算(800MOPS)。可重组式记忆体阵列架构(CMA)可根据应用程式的需求,重组成(图一)中,不同型式的暂存器集(Register files)。为了更降低功率,资料路径前回馈(Data forwarding)与时脉截止电路(Clock gating)同时被引用与各个管路间(Pipeline stage)与处理单元(Process element),并可直接由指令集控制。
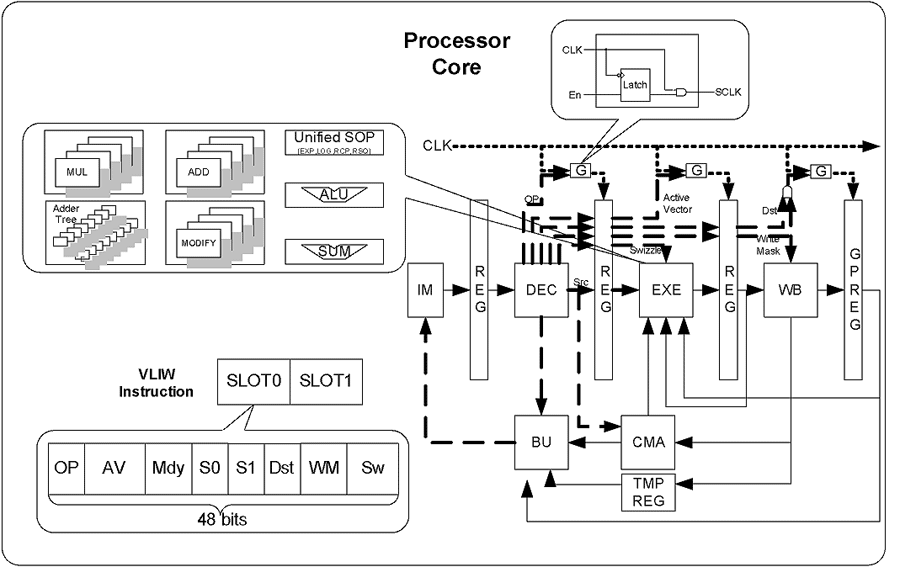
| 《图二 串流处理器核心架构》 - BigPic:899x566 |
|
可调适性多执行绪技术
可调适性多执行绪技术(AMT)结合资料路径前回馈辅助,可大幅减低资料危障(Data hazard)的发生机率,降低管路间停滞(Pipeline stall)增进执行效能. 甚至,可减少暂存器集的存取次数进而降低功率的消耗。可调适性多执行绪技术(AMT)有效率的使用了最少的执行绪而达成最大的隐藏执行周期(Hidden latency cycles)。 (图三)为可调适性多执行绪(AMT)与传统执行绪[3]的执行排程示意图。图中,材质载入指令(TxLoad)需要六个执行周期。在传统的多执行绪架构下,只有四个执行绪是无法完全隐藏执行周期的。相较于传统执行绪,可调适性多执行绪(AMT)会针对目前执行的指令来判断是否要改变目前的执行绪来达到最大的隐藏执行周期。由图可知,同样为四个执行绪,此技术可以完全隐藏材质载入指令。
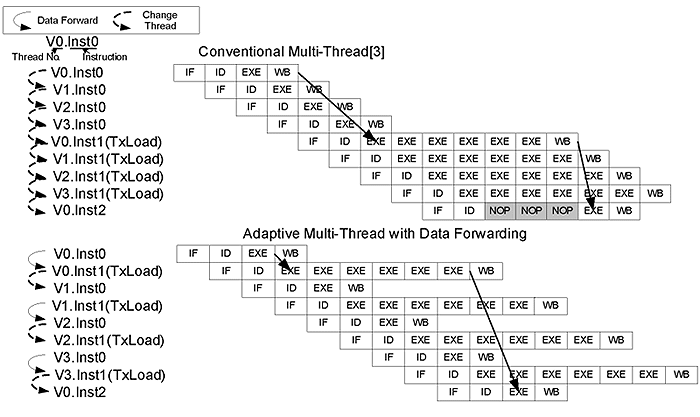
| 《图三 多线程执行排程》 - BigPic:699x416 |
|
可重组式记忆体阵列架构
在手持式行动装置中记忆体频宽是非常重要的资源。因为在有限的电池能量下,记忆体存取占了相当大的功率消耗比重。在我们提出的串流处理模型中,根据不同的应用同时采用了快取记忆体(Cache)与紧密偶合记忆体(Tightly coupled memory)技术大幅的降低外部记忆体的频宽。根据实验,在绘图处理时可以达到60%顶点快取击中率,且减少重覆顶点资料的存取与消耗功率;在执行移动估计(Motion estimation)的时候,我们的架构能支援等级C的资料重复利用技术[6]达到节省86%的记忆体频宽。可重组式记忆体阵列架构(CMA)使用了四通道与八个实体记忆体库以提供晶片内记忆体资源(On-chip memory pool)。此记忆体资源逻辑上映射至 (图一)中的各项暂存器集可以作为串流快取记忆体以及常数参考记忆体。而可重组的特性使得,针对不同的应用可以分配不同大小的记忆体给串流快取记忆体或其他的暂存器集进而达到最高的记忆体利用率。 (图四)表示不同的应用下,可重组式记忆体阵列(CMA)中的资料组织与分配。
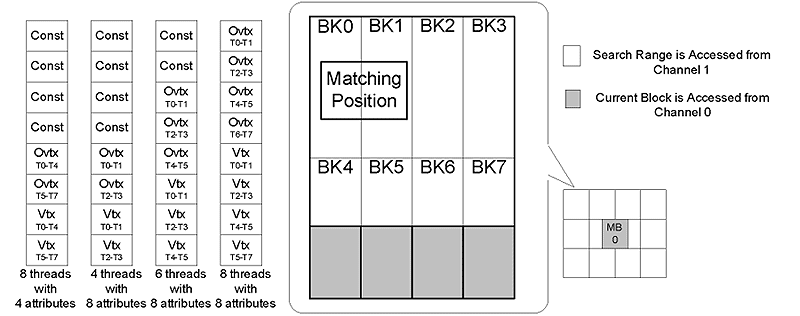
| 《图四 可重组式内存数组中数据组织示意图》 - BigPic:799x315 |
|
几何转换后滤除模组
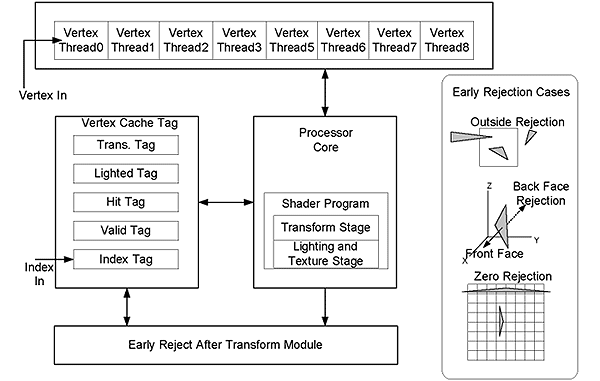
| 《图五 几何转换后滤除模块》 - BigPic:599x380 |
|
在三维绘图处理管路中,顶点处理器进行几何物件(Primitive)中所有顶点的几何转换 (Geometry transform),打光(lighting)以及贴图(Vertex texturing)运算。在将渲染(Shading)过后的顶点送至像素处理器的时候,根据实验会有一部分的几何物件无法呈现于屏幕而被遮盖掉, 这导致了顶点处理器消耗了多余的功率在无法被视见的几何物件上。我们在此提出了几何物件内容导向(Geometry-content-aware technique)的技术称为几何转换后滤除(ERAT)技巧。此技术可以在顶点处理器中当几何转换处理完毕,即可判别几何物件的视见率,提早滤除无法被视见的几何物件进而省去大量功率提升顶点的产出率。我们使用了独立的几何转换后滤除(ERAT)模组来侦测无法视见的几何物件。 (图五)说明了几何转换后滤除模组,串流处理器与串流快取记忆体的协同运作。右侧图则表示三种可被侦测的无法视见几何物件。
晶片实作
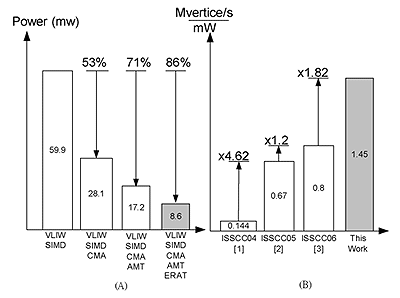
这颗晶片使用了台积电0.18微米制程,晶片大小为8.91mm2频率为50MHz。此晶片的功能特色如下表所示,量测到的功率为8.6mw,晶片如(图六)所示:
(表一) 晶片规格
Process Technology |
TSMC 0.18um CMOS 1P6M |
Chip Size |
2.7mm x 3.3mm |
Supply Voltage |
1.8V |
Clock Frequency |
50MHz |
Power Consumption |
(*)8.6mw |
Features
|
OpenGL ES 2.0 Support
Shader Model 3.0
Video encoding IME capability |
|
| (*)Shader Program Specular Light with 20 instructions |
(图七)呈现了功率消耗与执行效率比较图。当所有的主要技术被同时引用时,功率消耗可以减少86%相较于只使用超长指令集核心架构。我们也使用了效能比(Performance index),每秒每瓦有多少的顶点产出率,来评比我们的架构与之前发表过的晶片。可以看出,我们能达到1.82倍的效能比向较于之前顶尖的晶片。
结论
此8.6mw低功率多媒体串流处理器,能达到12.5百万的顶点输出,且在视讯压缩上使用完全寻找移动估计演算法能达到每秒30张CIF解析度(352x288)。整个核心的晶片大小仅有8.91mm2能达到同时满足手持式行动装置平台上三维绘图与视讯压缩的所需的处理能力。
此研究成果已发表于2007年国际超大型积体电路设计会议(2007 Symposium on VLSI Circuits)
曹友铭先生为国立台湾大学电子工程博士候选人。
林昱呈先生为国立台湾大学电子工程硕士。
孙志豪先生为国立台湾大学电子工程研究所硕士班学生。
陆家恒先生为国立台湾大学电子工程研究所硕士班学生。
简韶逸先生为国立台湾大学电子工程博士, 现任国立台湾大学电机系助理教授。
参考文献
[1] F. Arakawa. “An embedded processor core for consumer applications with 2.8gflops and 36m polygons/s fpu,” ISSCC Digest of Technical Papers, pp.334-335, 2004.
[2] J. Sohn. “A 50 mvertices/s graphics processor with fixed-point programmable vertex shader for mobile applications,” ISSCC Digest of Technical Papers, pp.192-193, 2005.
[3] C. Yu. “A 120没vertices/色彩multi-threaded v礼物vertex processor佛瑞mobile multimedia applications%2C” ISSCC Digest of Technical Papers%2C pp.408-409%2C 2006.
[4] K. Gray. “DirectX 9 Programmable Graphics Pipeline,” Microsoft Press, 2003.
[5] U. J. Kapasi. “Programmable stream processors,” Computer, pp.54-62, August 2003.
[6] J. Tuan. “On the data reuse and memory bandwidth analysis for full-search block-matching vlsi architecture,” IEEE Trans. Circuits Syst. Video Technol, pp.61-72, January 2002
[7] Y. M. Tsao. “Low Power Programmable Shader with Efficient Graphics And Video Acceleration Capabilities for Mobile Multimedia Applications,” ICSE Digest of Technical Papers, pp.395-396, 2006.