
在半導體製造邁入3奈米甚至更先進製程的今日,晶圓廠(Fab)面臨著前所未有的挑戰。虛擬量測技術是半導體產業從經驗驅動轉向數據驅動的里程碑。它不僅解決了實體量測的瓶頸,更為晶圓廠提供了製程透明度。
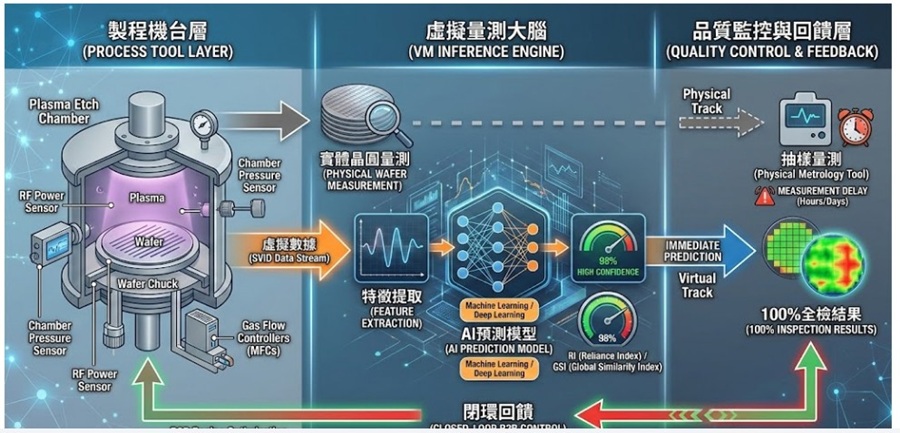
一片晶圓的生產週期長達數月,需經過上千道複雜工序。傳統的品質控管依賴於「實體量測」(Physical Metrology),即在特定工序後,將晶圓送往量測機台(如 CD-SEM、Scatterometry)進行抽檢。

|
半導體製造的「品質盲區」
這種模式存在三個致命痛點:
1.抽檢缺口:由於量測設備昂貴且耗時,通常一個卡匣(Cassette)25片晶圓中僅抽測 1 片。其餘 24 片的品質處於「未知」狀態,這就是所謂的品質盲區。
2.量測延遲(Metrology Delay):實體量測往往在加工完成後的數小時甚至數天後才執行。若機台發生偏移(Drift),等發現問題時,產線上可能已有數千片晶圓淪為廢品。
3.成本高昂:為了校正機台,廠內必須投入大量的「控片」(Monitor Wafer),這不僅浪費材料,也佔用了寶貴的產能。
因此,虛擬量測(Virtual Metrology, VM)應運而生。它並非真的「去量測」,而是透過機台感測器數據(Sensor Data),結合先進的數學模型,「預測」出每一片晶圓的加工品質。這項技術讓半導體廠從「抽檢」走向「全檢」,是實現工業4.0智慧製造的核心。
從感測器數據到品質預測
虛擬量測的本質是建立一個高度複雜的函數映射。假設機台的感測器參數為X,最終的品質結果(如蝕刻深度、薄膜厚度)為Y,VM的目標就是精準找出 f(X) = Y這樣的函數。
在半導體機台中,每秒會產生數以百計的狀態變數(SVID),包括:
‧ 氣體流量(Gas Flow)
‧ 反應室壓力(Chamber Pressure)
‧ 射頻功率(RF Power)
‧ 晶圓靜電吸盤電壓(ESC Voltage)
這些原始數據(Raw Data)充滿雜訊,且不同感測器的採樣頻率不一。因此,第一步必須進行特徵工程(Feature Engineering),將時間序列數據轉化為統計特徵(如平均值、標準差、斜率),並透過主成分分析(PCA)進行降維,剔除不相關的干擾項。
雙階段虛擬量測(Dual-Phase VM)是由業界廣泛採用的指標性技術架構。其運作邏輯如下:
‧ 第一階段(即時預測):當晶圓在反應室加工結束的一瞬間,系統立即抓取感測器特徵,投入預測模型,產出「預測值」。
‧ 第二階段(動態校正):當這片晶圓(或後續抽測片)完成了實體量測後,系統會比對「預測值」與「真實量測值」的誤差,並利用該誤差自動微調模型參數,確保模型能追蹤機台的老化與漂移。
信心指標(Reliance Index, RI)與全球相似指標(GSI)則是關乎半導體廠是否「敢於相信」VM 結果的關鍵。
‧ RI(信心指標):評估預測值的準確度。若 RI 越高,代表模型對此筆數據的預測極為可靠。
‧ GSI(全球相似指標):評估目前的機台感測數據是否超出了模型訓練時的範疇。如果 GSI 過高,代表這是一個「從未見過」的異常製程狀況,系統會主動發出警告,提示工程師此時的 VM 預測值不可信,應改採實體量測。
從統計回歸到深度學習
早期的VM主要採用多元線性回歸(MLR)或偏最小平方回歸(PLS)。這些方法優點是運算快、可解釋性高,但在面對高度非線性的半導體製程(如電漿蝕刻)時,精準度往往受限。
隨著AI技術成熟,現代虛擬量測已大量導入:
‧ 人工神經網路(ANN):能捕捉極其複雜的非線性關係。
‧ 隨機森林(Random Forest)與 XGBoost:對於處理機台的大量分類特徵與數值特徵具有極佳穩定性。
‧ 長短期記憶網路(LSTM):專門處理具有時間相關性的感測器序列數據,能預測機台隨時間產生的衰減趨勢。
半導體製程中的關鍵應用場景
1.蝕刻製程(Etching):關鍵尺寸(CD)預測
在蝕刻過程中,電漿的穩定性直接影響線寬(Critical Dimension)。透過監測電漿的光學發射光譜(OES)數據,VM 可以預測蝕刻深度,避免過度蝕刻導致電路毀損。
2.薄膜沉積(CVD/PVD):厚度均勻度
薄膜的厚度分布對後續製程至關重要。VM 能即時分析氣體流量與溫度分佈,預測晶圓表面各點的厚度,實現對每一片晶圓的品質監控。
3.化學機械平坦化(CMP):移除率預測
CMP製程中,研磨墊(Pad)的磨耗與研磨液(Slurry)的濃度會不斷變化。VM結合R2R(Run-to-Run)控制,能預測移除率(Removal Rate),並自動計算下一片晶圓所需的研磨時間,大幅提升製程平整度。
虛擬量測與先進製程控制
|
虛擬量測若僅僅是「預測」,價值僅發揮一半。其真正的威力在於與先進製程控制(APC)的深度整合。在現代Fab中,VM被視為APC的「眼睛」。
當VM預測出當前晶圓的薄膜厚度略微偏離目標值(Target)時,系統會立即將此偏移量回傳給Run-to-Run(R2R)控制器。控制器會根據模型計算,自動調整下一片晶圓的配方參數(例如增加2秒的加工時間),達成自動補償。
此外,VM也能推動控片減量。過去工程師每天必須跑數片控片來確認機台狀態,現在透過VM的高信心度預測,可將控片數量減少50%以上,直接轉化為數百萬美元的成本節省。
資料治理與模型韌性
雖然虛擬量測在理想環境下能展現極高的預測精度,但半導體製造是一個高度動態且對變異極度敏感的環境。要不間斷運行的晶圓廠中落實 VM,必須解決兩個核心挑戰:資料的真實性與模型的適應能力。
因此,建立VM系統的第一步並非建模,而是資料清洗與降噪。工程師會導入FDC(Fault Detection and Classification)系統作為前哨。
Garbage In, Garbage Out
虛擬量測完全仰賴機台感測器回傳的數據。然而,感測器本身也會發生偏移或故障。例如,一個壓力計可能因為製程副產物的堆積而產生數值漂移,或者流量控制器(MFC)因老化導致輸出不穩。
VM系統必須先過濾掉機台異常停機、暖機階段或感測器失效的數據。此外,由於半導體機台參數動輒上千個,如何從中篩選出真正影響品質的「關鍵特徵」至關重要。這通常需要結合製程工程師的領域知識與統計學上的相關性分析,確保模型輸入端的純淨度。
模型的遷移學習與適應
半導體產線通常擁有數台、甚至數十台執行相同工序的機台。即便型號完全相同,不同機台(或同一機台內的不同反應室)之間仍存在微小的物理差異。如果為每一台機台單獨訓練模型,將耗費龐大的計算資源與標記資料(量測值)。現代VM技術正導入遷移學習(Transfer Learning)來解決此問題。
機台的物理狀態會隨著生產次數增加而改變,例如蝕刻室壁的聚合物堆積或零件更換。一個固定的VM模型在運行三個月後,精準度往往會大幅下滑。因此,卓越的虛擬量測系統必須具備「自動刷新機制」。
當系統偵測到預測值與實體量測值的殘差持續擴大,但信心指標卻維持高位時,系統會自動觸發重新訓練程序。這種自動化的閉環訓練能確保模型始終追蹤機台的最新狀態。更先進的做法是導入線上學習,即時地微調內部參數。
結語
隨著5G與邊緣運算的普及,VM的運算將從秒級縮短至毫秒級,實現真正的「零延遲、全自動」自我修復生產線。
虛擬量測技術是半導體產業從「經驗驅動」轉向「數據驅動」的里程碑。它不僅解決了實體量測的瓶頸,更為晶圓廠提供了製程透明度。在全球半導體競賽中,誰能更精準地掌握虛擬量測,誰就能在良率與成本的戰爭中取得絕對領先。