简介
当闪存仍然在嵌入式系统的储存装置上占有一席之地的同时,它的应用已超出其原本的设计。近年来,它已经成为许多系统设计中重要的一环,其中著名的例子有英特尔提出使用闪存来当作硬盘高速缓存的架构,还有微软提出Windows Vista系统的快速开机服务 [1, 6, 9],此类的应用对闪存的使用寿命及可靠性造成极大的挑战;更甚者,在低价闪存市场日益扩大的趋势之下,对闪存可靠性所造成的冲击是更加严重。例如:传统的SLC (Single-Level Cell,代表每个储存数据的单位可存一个位的数据) 闪存的每个区块可被抹除的限制为100,000次,而现在的MLCx2 (Multi-Level Cell,代表每个储存数据的单位可储存两个位的数据) 闪存的每个区块的抹除限制降至10,000次,未来随着每个 Cell可存放的位数的增加,闪存的使用寿命将势必减短。这样的观察点出了快闪记体上数据可靠性的问题。然而,在实用及市场上不太可能接受大幅提高系统硬件效能及成本的做法,因此提出并研发一个既省主存储器又能与当前系统兼容的方法来有效提升闪存寿命的方法实为一重要的课题。
一个NAND型闪存芯片含多个区块,每个区块包含多个页面,一个区块是抹除动作的最小单位,而读写的最小单位是一个页面。大区块的SLC闪存中,每个页面(page)通常包含2KB的空间外加64B额外空间,而每个区块(block)包含64个页面;小区块的SLC闪存中,每个页面通常包含512B的空间外加16B的额外空间,而每个区块包含32页面。另外,MLCx2闪存,每个页面通常包含2KB的数据外加64B的额外空间,而每个区块包含 128 个页面。通常闪存会被一个「成组设备转换层」所管理,著名的管理方法有Flash Translation Layer协议 (FTL)及NAND Flash Translation Layer (NFTL)协议,这样的管理层通常是由主机上的软件来实作,或是实作在装置内部以硬件或韧体的形式存在。在过去的研究中,有许多关于闪存的杰出研究或实作,它们主要是用来提升闪存的读写效能 [2, 3, 4, 5, 11, 12, 17, 18],另外有一些则是研究闪存可以被应用的其它层面,例如:大容量的储存系统及数据压缩 [11, 17, 18]。
因为闪存每个页面被写入数据之后就不能再被修改,除非被抹除之后才能够再写入新的数据,因此具有「外部更新」(out-place updates)的特性,也就是要被更新的数据必须要写在另外一处尚未被写过数据或刚被抹除的页面之中,而原来储存旧数据的页面就要被标示为「过期」(invalid)的数据,而外部更新的特性引发了闪存的平均抹除议题,因为任何过期页面的回收都会引发区块抹除的动作,而平均抹除是用来使区块抹除的分布较为平均,使得每个区块被抹出的次数一样或较为平均,这样可以延长闪存的使用寿命。以这个方式为目标,许多不同的动态平均抹除方法被提出来,例如 [7, 10, 11],但是动态平均抹除方法通常会试着去抹除有效数据较少的区块。这样的方法需高效率的的方法来分辨 经常被更新的数据(hot data),也因此有许多方法被提出,例如:[11, 13, 14, 15]。仅管动态平均抹除可以大幅改善内存的平均抹除程度,但是对内存寿命的延长仍受到极大的限制,这是因为存放不常被更新的数据(cold data)的区块通常不会被选来做抹除,最后使得部分区块被抹除的次数特别少。相反的,静态平均抹除和动态平均抹除方法不同,它会试着去抹除内存中的任何区块,使得没有任何数据能存在任何一个地方太久。
仅管静态平均抹除对内存寿命能有大幅的提升,但是非常少的研究着重在这个议题之上 (除了如[7, 16]等产品上有提到这个议题之外),因此我们提出一个静态平均抹除的机制来提升闪存的使用寿命,并且只使用非常少量的主存储器及增加非常少量的系统负荷;其中,一个管理的数据结构及一个队列式检视的程序被提出来达成静态平均抹除的目的,并且能与现行的管理机制(FTL及NFTL)兼容。这个机制的行为及特性亦被详细地验证过,诸如主存储器需求、额外的区块抹除及额外的有效页面数据复制。我们做了一系列的实验来证明我们所提出的论点,依据实验结果,我们所提出的方法在第一次区块损坏的发生时间为考虑的话,搭配FTL管理的闪存寿命可提升51.2%,且可以提升使用NFTL的闪存寿命高达 87.5%。
系统架构
这个机制的行为及特性亦被详细地验证过,诸如主存储器需求、额外的区块抹除及额外的有效页面数据复制。我们做了一系列的实验来证明我们所提出的论点,依据实验结果,我们所提出的方法在第一次区块损坏的发生时间为考虑的话,搭配FTL管理的闪存寿命可提升51.2%,且可以提升使用NFTL的闪存寿命高达 87.5%。
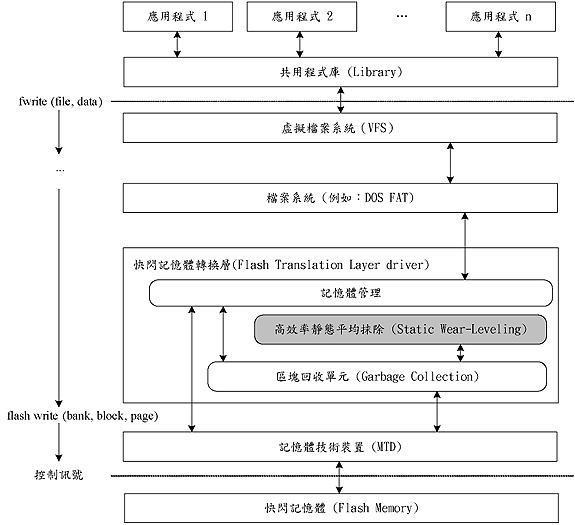
| 《图一 常用文件系统所使用的系统架构》 - BigPic:574x524 |
|
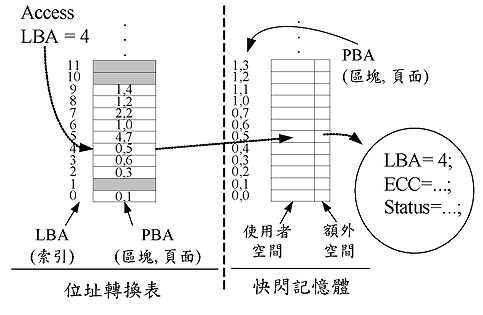
常用文件系统所使用的系统架构如(图一)所示为一个常用文件系统所使用的系统架构,其中包含一个MTD (内存技术装置、Memory Technology Device)驱动程序用来提供基本的函数及功能,如读、写、抹除等基本功用的函数,另外包含一个「闪存转换层」,是用来做内存管理及区块回收,而 FTL及NFTL就是这一层的管理机制。在这一层中,内存管理是用来做地址转换,也就是来自上层的LBA (逻辑区块地址、Logical Block Address)与下层物理内存的PBA (实体区块地址、Physical Block Address)之间做转换,而不同的方法采用不同的方式来管理LBA与PBA之间的转换。
区块回收单元则是用来回收存有过期数据的页面,但因为数据抹除的单位是以区块为单位,因此需要先把区块内的有效数据复制到其他地方,然后再将整个区块抹除,而选择被被抹除区块的方法直接影响到内存寿命,因此突显平均抹除技术的重要性。
现在闪存转换层的重要实作FTL [2, 3, 5] 采用「页面单位」的管理机制,也就是每个实体页面都会有一个相对映LBA 与PBA之间的转换信息,(图二)的表格中所记的信息就属于这一类的地址转换,例如LBA4实际上是被储存在实体的「区块0」中的「页面5」,也就是PBA=(0,5)的地方,其中LBA是操作系统所管理的页面(或区段)地址。当有任何数据被更新时,FTL必须找一个空的页面来存放新的数据。
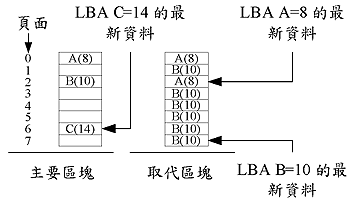
FTLNFTL使用「区块单位」的管理机制,也就是每个区块才有一个地址转换的信息。在此机制之中,每一个LBA被分为VBA(虚拟区块地址、Virtual Block Address)及区块offset (也就是「LBA」除以「一个区块内可存LBA个数」的余数),一个VBA会依据地址转换表内的数据找到它的实体区块。
NFTL
高效率静态平均抹除机制
概要
静态平均抹除是为了要防止任何数据留在任意一个区块内太久,也就是要缩小任两个区块的抹除次数的差别。这此论文之中,我们考虑一个模块化设计的架构,因此可以轻易地整合进许多现行的管理机制之中。如(图一)所示,我们提出的架构就是将高效率静态平均抹除机制变成一个嵌入闪存转换层中的一个模块,它会引导块块抹除模块去抹除高效率静态平均抹除机制所指定的区块。高效率静态平均抹除机制中有一个BET (区块抹除表、Block Erasing Table),是用来记录在一段时间区间之内区块被抹除的分布情况。高效率静态平均抹除机制是经由一些系统参数来决定启动的时机,当它被启动之后会重设BET内的所有信息或是依据BET内所纪载的信息来选取要回收的区块(组),并利用引导块块回收单元来完成有效页面数据的搬移及区块抹除的动作。
其中选择回收区块必须要非常有效率,且每当一个区块被抹除时,BET的内容必须要正确地被更新。因为闪存的容量快速增大及控制器上容量有限的RAM (随机存取内存),所以BET 的设计必须要具有可扩充性。此外,高效率静态平均抹除机制可以是一个线程或程序,可以透过内存管理机制来触发执行。
区块抹除表(BET)BET的目的是用来记录在一个默认的时间范围内的区块抹除情形,用以侦测存放不常更新数据的区块之所在,这个默认的时间范围称为「重置区间」(resetting interval)。BET是一个位数组 (bit array),每个位为一个旗标,每个旗标对映到连续2k个区块,其中k为一个0或大于0的整数。一开始时,BET内的所有旗标都被设为0,每当区块回收单元抹除一个区块时,静态平均抹除机制会被启动来将该被抹除区块相对映的旗标设为1。

| 《图四 旗标与区块的对映机制》 - BigPic:680x300 |
|
旗标与区块的对映机制最坏状况出现在当k值很大且经常更新与不常更新的数据存在同一个区块组 (一个区块组就是被同一个旗标所对映到的一组连续区块) 里,幸运的是:这样的情况会随着时间自然地解决,原因是当页面所存放的数据是经常更新的数据,则该页面所存的数据很快就会过期,结果不常更新的数据最后还是会被率静态平均抹除程序要求搬到其他地方。技术上的问题是依据解决此状况所需的时间(偏好小的k值)及可用的RAM的空间 (偏好大的k值)。另一个技术问题是当系统启动时,重建BET所需的时间,一个简单有效方法是在系统关机时,将BET存放在闪存内,并且在系统重新启动时重载BET。如果系统没有正常关机,我们可以加载任何现存BET的正确版本,只要不常发生系统不正常关机的情况,这样的解决方法相当合理,原因是我们只损失少量的抹除记录,并不会影响整体的效能。
因为每一个区块组只需要一个位,所以整个BET所需要的内存空间很小。如表一所示,BET 的大小依据闪存的大小及k值的大小而定。举例而言,一个4GB SLC大区块的闪存需要512B来存放BET。当然,如果使用MLC闪存的话,BET的大小就会更小。
(表一) SLC闪存的BET大小
|
128MB |
256MB |
512MB |
1GB |
2GB |
4GB |
k = 0 |
128B |
256B |
512B |
1024B |
2048B |
4096B |
k = 1 |
64B |
128B |
256B |
512B |
1024B |
2048B |
k = 2 |
32B |
64B |
128B |
256B |
512B |
1024B |
k = 3 |
16B |
32B |
64B |
128B |
256B |
512B |
静态平均抹除机制
静态平均抹除机制包含BET及两个子程序SWL-Procedure及SWL-BETUpdate (参见图五及图六)来达成静态平均抹除的目的。每当区块回收单元抹除一个区块,它就会呼叫SWL-BETUpdate,并依新被抹除的区块来更新BET。SWL-Procedure是当需要做静态平均抹除的时候才会被呼叫,而呼叫的时机是经由fcnt及ecnt等两个变量所决定,其中fcnt表示BET中被设定的旗标个数,ecnt表示自从上次BET被重置之后抹除区块的总次数。当fcnt/ ecnt的值 (我们称为「不均匀程度」(unevenless level) )大于或等于所设定的门坎值T时,SWL-Procedure就会被启动来检查BET,从中找出一些很久没有被抹除过的区块,并要求区块回收单元将这些被选上的区块抹除并回收,这样一来不常被更新的数据就会被强迫存放到别的地方去。值得一提的是:不均匀程度越高,表示越多的区块抹除都集中在小部分的闪存区块中。
(图五)是SWL-Procedure的算法:如果BET才刚被重设过的的话,fcnt会等于零,因此 SWL-Procedure就会直接返回(步骤1)。当不均匀程度大于或等于默认的门坎值T时,区块回收单元在每一个循环中都会被呼叫起来抹除所选定的一组区块(步骤2-15)。在每一个循环的一开始都会先检查是否BET内的所有旗标都已被设定(步骤3);如果是的话,就会把BET内的所有旗标都重设为0,并将其他参数都清为0 (步骤4-7),值得一提的是:findex是在做静态平均抹除时用来指出被选到的区块组,并且每次重设时它都会被随机的设定指到任意的一个区块组。在BET及其它参数都重设后,SWL-Procedure就会返回以开始下一个重设区间(步骤8),否则选取指针findex就会移动到下一个尚未被设定的旗标以找到很久都没被抹除过的区块组(步骤10-12),值得注意的是:循序扫描每一个区块组在实作上是非常快速且有效的做法,因为我们发现不常被更新的数据可能被存在闪存中的任意区块中,所以循序找一个尚未被抹除过的区块组与随机找是一样的效果。SWL-Procedure接着会呼叫区块回收单元来将所选中的区块组(findex所指的旗标所对映的区块组)抹除(步骤13),然后移动到下一个旗标(步骤14)。我们必须指出来的是:因为SWL-BETUpdate会在区块回收单元抹除一个区块后被呼叫,因此fcnt和 BET都会自动被正确地更新。这个循环一会直执行到不均匀程度降到比默认的门坎值还低为止。

| 《图五 算法之一》 - BigPic:592x505 |
|
SWL-BETUpdate的算法如图六所示:给定被区块回收单元所抹除的区块的地址 bindex,SWL-BETUpdate首先将被抹除的区块总数加1 (步骤1),如果该区块所对映的旗标尚未被设定的话,就会把该旗标设定,并且将被设定的旗标总数值加1 (步骤2-4)。

| 《图六 算法之二》 - BigPic:592x255 |
|
最后的技术问题是如何维护 ecnt、fcnt及findex的值。为了让静态平均抹除能得到较好的效果,这些变量的值必须储存在闪存之中,但是我们必须指出:这些值是可以忍受错误的,也就是如果这些值尚未被写入闪存中,系统就当机的话,我们可以在下一次开机时直接加载上次存在闪存中的旧值,因为失去小段时间的区块抹除状况的记录并不影响静态平均抹除的效能。
效能评估
实验设定
本文的目的是为了评估我们所提出的平均抹除机制在FTL及NFTL上的效能,尤其是使用寿命及此机制所带来的额外负荷。使用寿命基于「第一次发生区块损坏」来做分析评量;而额外负荷是利用「额外区块抹除」及「额外页面复制」来做评量。
为了使比较具公平性,无论有没有加入我们所提出的平均抹除机制,都同样在FTL及NFTL中使用greedy的方法:也就是在选择一个即将被抹除的区块时,如果区块中有一个页面里所存的是有效数据,那么就会增加一个单位的抹除负荷,如果有一个页面里所存的是过期数据,则就会增加一个单位的利益;当一个被检视的区块内的总页面利益大于总页面负荷时,就会被区块回收单元所抹除,而区块回收单元在整个系统中闲置区块量低于总区块量0.2%时,就会被启动来进行区块抹除,以回收一些储存过期数据的空间。值得注意的是:当NFTL的一个取代区块要被抹除时,NFTL会将取代区块及其相对映的主要区块内的有效数据合并到另一个区块中,并同时把这两个区块一起抹除。
实验中,我们使1GB MLCx2的闪存(每个区块128个页面,每个页面可存放2KB的数据)为对象,虽然FTL及NFTL的原始设计都不能使用在MLC闪存上,但是只需要小修正就可以管理 MLC闪存,因此不是一个大问题。这1GB的闪存最多可以存放 2,097,152个LBA的数据。另外,实验中所使用的数据存取记录是搜集一台装配有20GB硬盘的笔记本电脑上一个月的硬盘存取记录而来的,而这台计算机在搜集期间主要是用在浏灠器的使用、电影片的下载及播放、计算机游戏的执行及文件编辑。在此存取记录中约有36.62%的LBA有被写过,而平均每秒钟的写入次数为1.82次、读取次数为1.97次,但只有存取前2,097,152个LBA的数据才会被使用在实验中。为了使闪存发生第一次区块损坏,所以我们随机从搜集到的存取记录中选择一个10钟长度的存取记录的片段,且每个被取过的段断还是有机会被重取,这样就可以产生一个虚拟的无限长度存取记录。
使用寿命的延长
(图七)显示我们所提出的静态均匀抹除机制搭配FTL或NFTL时皆可大幅延缓第一次区块损坏的时间;换句话说,也就是可以大幅延长闪存的使用寿命并提高可靠性。图中的x轴表示k的值,y轴表示的是第一次发生区块损坏的时间(以年为单位)。举例来说:当T = 100且k=0时,静态均匀抹除机制搭配FTL可以提升闪存51.2%的使用寿命,而搭配NFTL时可以提升87.5%的使用寿命。一般而言,小的T及k值搭配NFTL可以有比较好的效能,因为T影响静态均匀抹除机制被启动的频率,而k影响BET对不常更新数据的辨识力。
有趣的是当静态平均抹除机制搭配FTL时,反而是当T小一点但k大一点时的表现比较好,原因是因为FTL是页面单位的地址转换机制,当k值大一点的时候,静态平均抹除机制一次要求区块回收单元抹除的区块比较多,也就是一次会搬移比较多的(静态)数据,反而把经常更新与不常更新的数据分离的更清楚,这使得存放经常更新数据的区块会更快被损坏。值得一提的是:虽然FTL发生第一次区块损坏的时间比较慢,但是在大容量的闪存的应用上是不实际的,因为每个页面都需要一个地址转换,因此需要非常大容量的RAM来维护地址转换表。
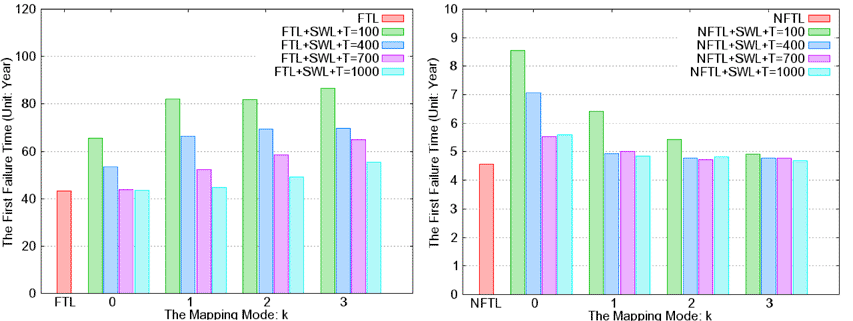
| 《图七 第一次区块损坏的时间》 - BigPic:852x320 |
|
额外负荷
(图八)显示的是所提出的静态均匀抹除机制搭配FTL或NFTL时所增加的区块抹除比例。一般而言,当T大一点(启动频率降低)及k值大一点(BET的分辨率降低)时,所增加的负荷就会比较小。整体来看,所增加的比例在FTL上都小于3.5%,而在NFTL上都小于1%。
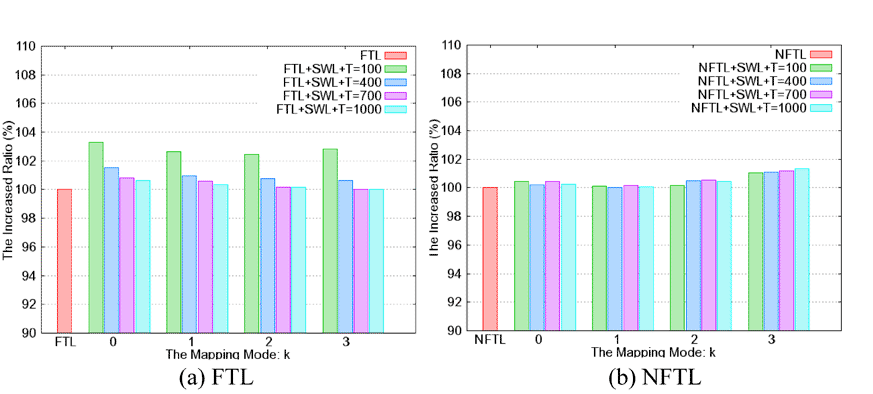
| 《图八 增加区块抹除的比例》 - BigPic:872x393 |
|
(图九)显示的是所提出的静态平均抹除机制搭配FTL或NFTL时所增加有效页面数据复制的比例。在搭配NFTL时,所增加的比率都小于1.5%。但在搭配FT时,所增加的比率就大上很多,这是因为经常更新的数据通常都是大量写入,导致被选上要回收的区块大部分都布满了过期的数据,即使如此,我们提出的静态平均抹除机制在抹除一个区块时,平均需要复制的有效数据页面数仍然非常小。
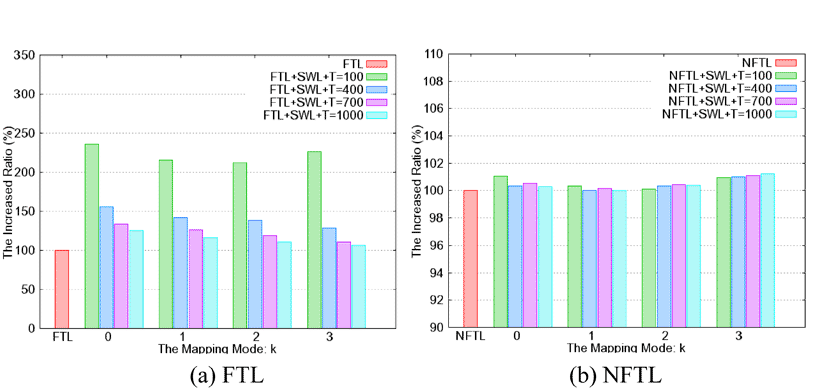
| 《图九 增加有效页面数据复制的比例》 - BigPic:820x391 |
|
结论
增加有效页面数据复制的比例
本文点出当闪存被使用在各种不同的应用时所引发的数据可靠性问题,也就是闪存的使用寿命。不同于之前动态平均抹除的研究,我们提出一个静态平均抹除的方法来提升闪存的使用寿命,且只需要极少量的额外RAM,且几乎不需要改变原来的闪存转换层的设计,就能使用我们所提出来的方法,同时又几乎不会增加系统负荷。一系列的实验也证明所提出的方法搭配FTL及NFTL都能对闪存提高一半以上的使用寿命。
未来,我们会进一步研究闪存的可靠性问题,尤其是MLC闪存所引起的新可靠性问题;另外,我们也会研究闪存被应用在外部装置上的行为及所引发的问题。
<张原豪先生为国立台湾大学信息网络与多媒体研究所博士班学生>
<谢仁伟先生为国立台湾大学信息工程研究所博士,现任国立嘉义大学信息工程系助理教授。>
本文给出电源设计中如何利用低端栅极驱动器IC的设计指南。其中包括如何选择适当的驱动器额定电流及功能,驱动器需要哪些支持组件,以及如何估算损耗和结温。在开关电源设计中,通过正确运用栅极驱动器IC,能够提高效率、减小尺寸并简化设计。
[1] Flash Cache Memory Puts Robson in the Middle. Intel.
[2] Flash File System. US Patent 540,448. In Intel Corporation.
[3] FTL Logger Exchanging Data with FTL Systems. Technical report, Intel Corporation.
[4] Flash-memory Translation Layer for NAND Flash (NFTL). M-Systems, 1998.
[5] Understanding the Flash Translation Layer (FTL) Specification, http://developer.intel.com/. Technical report, Intel Corporation, Dec 1998.
[6] Hybrid Hard Drives with Non-Volatile Flash and Longhorn. Microsoft Corporation, 2005.
[7] Increasing Flash Solid State Disk Reliability. Technical report, SiliconSystems, Apr 2005.
[8] NAND08Gx3C2A 8Gbit Multi-level NAND Flash Memory. STMicroelectronics, 2005.
[9] Windows ReadyDrive and Hybrid Hard Disk Drives, http://www.microsoft.com/whdc/device/storage/hybrid.mspx. Technical report, Microsoft, May 2006.
[10] A. Ban. Wear leveling of static areas in _ash memory. US Patent 6,732,221. M-systems, May 2004.
[11] L.-P. Chang and T.-W. Kuo. An Adaptive Striping Architecture for Flash Memory Storage Systems of Embedded Systems. In IEEE Real-Time and Embedded Technology and Applications Symposium, pages 187.196, 2002.
[12] L.-P. Chang and T.-W. Kuo. An Efficient Management Scheme for Large-Scale Flash-Memory Storage Systems. In ACM Symposium on Applied Computing (SAC), pages 862.868, Mar 2004.
[13] M.-L. Chiang, P. C. H. Lee, and R.-C. Chang. Using data clustering to improve cleaning performance for flash memory. Software: Practice and Experience, 29-3:267.290, May 1999.
[14] J.-W. Hsieh, L.-P. Chang, and T.-W. Kuo. Efficient On-Line Identification of Hot Data for Flash-Memory Management. In Proceedings of the 2005 ACM symposium on Applied computing, pages 838.842, Mar 2005.
[15] J. C. Sheng-Jie Syu. An Active Space Recycling Mechanism for Flash Storage Systems in Real-Time Application Environment. 11th IEEE International Conference on Embedded and Real-Time Computing Systems and Application (RTCSA'05), pages 53.59, 2005.
[16] D. Shmidt. Technical note: Trueffs wear-leveling mechanism (tn-doc-017). Technical report, M-System, 2002.
[17] C.-H. Wu and T.-W. Kuo. An Adaptive Two-Level Management for the Flash Translation Layer in Embedded Systems. In IEEE/ACM 2006 International Conference on Computer-Aided Design (ICCAD), November 2006.
[18] K. S. Yim, H. Bahn, and K. Koh. A Flash Compression Layer for SmartMedia Card Systems. IEEE Transactions on Consumer Electronics, 50(1):192.197, Feburary 2004.