DSP是因应二次大战期间军事上的需求而发展出来,在战后,DSP进入和平用途,应用在石油、深海矿物、卫星远距探戡或者气象分析上,直到1995年Intel将DSP嵌入CPU中,以多媒体指令MMX实现Dual Core发展出single chip解决方案,DSP才正式进入高阶且平价的消费市场,DSP SoC也同时在宽频通讯、数位控制、数位音频与数位视讯等众多市场获得肯定。
根据Forward Concepts报告显示,通讯仍然是今年DSP最大的应用市场,然而位居第二的消费性电子产品,随着数位化发展趋势,DSP又扮演着将类比转为数位的重要转换桥梁,预估自2004年起,DSP在消费性电子的应用将会挟带庞大影响力进入人们的生活。
由于大众对生活品质要求提高,同时带动了消费性电子产品的需求量,而声音在电子产品上的呈现要求,也从只是「聆听声音」进阶至「听觉享受」。 DSP能即时处理大量讯号、处理速度快且成本低,其高品质的表现结果成为数位资讯产品的核心,而现阶段音频讯号透过DSP进行处理的依赖程度也就日益加深。由于人类可接收的声音源是类比环境,(图一)是说明将输入的类比讯号转为数位讯号,再将处理过的数位讯号转为类比讯号过程。
DSP的应用领用相当广泛,在音讯上的工程技术包括回音消除、噪音抑制、语音处理(语音辨识、合成)、VOIP及声音压缩解压;在应用产品上有DVD/CD播放机、音响合成器、数位录音机、电子语音玩具、助听器与网路电话等。其中,音讯处理主要部份又可分为声音的处理及合成、音讯编码及语音辨识。
百变声音发明家─合成及处理
在音乐播放过程中,数位资料的呈现结果最重要是要防止在类比储存和运作时所造成的音质损耗。等化器(Equalizer)能将不同频率范围的讯号分别滤出,然后再各别放大或缩小处理,最后再合成,所以能补偿讯号的频率衰减,使音质回复原音,或者也能补偿输入的不足,使音质达到理想状态。由于人类的听觉系统在低频及高频的接收上灵敏度较差,透过Equalizer强化或补足声音的功能,能弥补人们在听觉上的盲点。例如:将频率为100Hz的组成泛音放大,就会让声音中100Hz左右的低频部份听起来震撼一些,若觉得声音的低频部份不够明显,也可以用等化器加以补足。像目前MP3播放器几乎都有Equalizer的功能,使用者可选定或自定不同的播放音场(摇滚、爵士、流行音乐、抒情),充份表现出音乐的个性化。另外,变声器(voice changer)是透过声音处理技术改变原始的音源呈现,此种技术可广泛应用在电话上做安全过滤或者调整播放音调及速度后,达到语音学习的目的,成为高阶语言学习机的必备功能。
创造声音的无限时间及空间─音讯编码
为了满足现代人对于储存容量的需求,利用音讯编码(Digital Audio Coding)可实现声音数位化后小体积、复制时不会失真、容易保存及保密等优点。音讯编码有许多种,针对声音的编码有PCM、ADPCM、DM、PWM、WMA、OGG、ACC、MP3Pro以及MP3等等,目前最常见的为MP3;针对人类语音有LPC、CELP与ACELP,文中会以CELP做介绍。
MP3声音编码
MP3是MPEG 1 Layer III的简称,是由MPEG(Moving Pictures Expert Group)所制定的影音压缩─声音部分。目前已在市场上销售的MP4,并非是MP3的延伸,MP4是指小尺寸萤幕的视讯产品,MP3具有可携式「随身听」的特色,而MP4的小萤幕设计却与人类一般的视觉习惯背道而驰,也减损了「随身看」的原意。
MP3的编码原理主要是利用人耳听觉的特性,从声音中去除人耳听不到的资讯。人耳因为构造的关系,在接收声音时均会在频率与时间上产生遮蔽效果(masking)。所以MP3根据这样的特性采取了「感官编码技术」(perceptual coding techniques),即编码时先对音频资料进行频谱分析,利用人耳听觉上的遮蔽效应,将量化杂讯限制在人耳无法察觉的范围内,除了能够提供高压缩效率,还能保持非常好的音质。
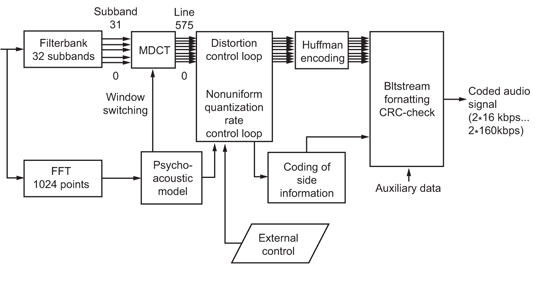
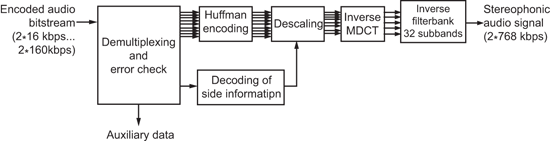
(图三)为MP3压缩编码的方块图,讯号输入为PCM格式2×768kbps,经过filter bank将讯号分为32个子频带,同时PCM讯号经FFT转换后,利用人耳的心理声学模型(Psycho- acoustic model),决定必须量化的频谱与量阶并进行第一次的编码(失真压缩)。编码结果再用无失真压缩作第二次编码(Huffman encoding)。最后因应通讯需求,加上封包资讯与错误更正码,即完成编码过程。而解码过程即为编码反运算(图四),将封包解开后,经过Huffman decoding,得到量阶与频谱,再经反离散余弦转换(IMDCT)及filter bank将各频谱讯号组合,即可还原成PCM讯号。
DSP大量使用在声音处理部份,像CD播放机的声音输出便是使用DSP进行Reed Soloman Code的编解码,因而即使音轨上有些许损毁,还是能自动更正错误,拨出毫无受损的音乐。此外,高阶DAC(Digital Analog Converter)中的△Σ也是利用DSP进行杂讯整型,可将讯号频带内杂讯抑制至最低而达到高讯杂比(SNR),让声音拥有更真实完美的呈现。
CELP语音编码(Code excited linear prediction)
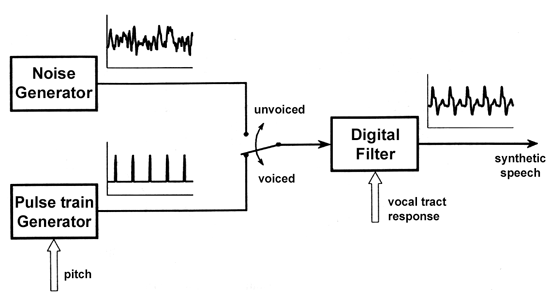
CELP是近来最成功的语音编码演算法,具有语音品质清晰及计算量合理之优点。 CELP是一种高效率(压缩比较高)的语音编码技术,由于采用了感觉加权、分析合成、向量量化和后滤波等技术,CELP能够在中低速率上完成高品质的合成语音。像同样128Mb Flash的记忆容量,以ADPCM进行编码,只有8小时的储存空间,而CELP编码却能达到36小时。不过,CELP在6~8k的频宽环境下使用,能维持较佳的音质,而在4kbps的速率时,激励码原始尺寸小,因此合成语音品质较差。为了提高此速率的合成品质,往往需要增加处理长度(例如30ms或更长),不过,这会使编码延长时间,另外还需要增加演算法复杂度和记忆体容量,才能得到令人比较满意的合成语音品质。目前CELP已经被许多语音编码标准所采用,除了高品质的窄带语音保密通信外,需要长时间录音(10小时以上)的消费性产品,如录音笔或录音棒也是使用CELP技术。
只动「口」不动手的年代─语音辨识
英特尔的创办人摩尔在接受媒体专访时,曾直指「语音技术」将是影响未来科技发展最关键的技术,「半导体教父」的预言,让语音技术的发展,顿时受到全球的注目。所谓语音辨识最主要目的是让电子设备,譬如电脑能听懂人类说话的语言或命令,而做出相对应的工作。当声音藉由类比到数位的转换装置输入电脑内部,并以数位方式储存后,语音辨识程序便开始启动,将事先储存好的声音样本与输入的声音样本进行比对工作。声音比对工作完成之后,辨识程式会输入一个它认为最“像”的声音样本序号,理解使用者刚刚发出声音的意义,进而命令电脑做事。
但要真正建立辨识率高的语音辨识程式,却是非常困难而专业的。例如:“声音样本”要如何建立呢?简单来说,如果要辨识10个字,那就是先把这10个字的声音输入电脑中,存成10个参考样本,辨识时,只要将本次所输入的声音(测试样本)与事先存好的10个参考样本一一对比,找出与测试样本最像的样本,即可把测试样本辨识出来。但是,别忘了语音讯号还有一项重要的特性:在不同时间,虽然说的是同一句话或相同的音,但其波形却不尽相同,也可以说语音是一种随时间而变化的动态讯号,做语音辨识就是要从这些动态讯号中找出规律性,一旦找到规律性之后,讯号再怎么变化,大致都能撷取出它们的特性,进而将它们辨识出来。这种规律性在语音辨识上称为特征参数,也就是能够代表讯号特性的参数,语音辨识的基本原理就是以这些特征参数做基础。
要建立一个语音识别系统仅有一组好的语音特征还不够,还要有一个好的语音识别模型和演算法。目前,在研发完成的语音识别系统中,基于统计的HMM演算法可能是最为成功的一种。现今所见的各种性能优良的连续语音识别系统,几乎无一例外地采用这种模型。这是因为这种数学模型出现的时间较早,人们对它的研究比较深入,也已建立起完整的理论框架。这种隐含马尔可夫模型的演算法是将语音看成是一连串特定状态,这种状态是不能被直接观测到的,而是以某种隐含的关系与语音的特征相关联。而这种隐含关系在HMM模型中通常是以机率形式呈现,输出结果也是以机率形式表示,为系统最后的稳健判断创造了条件。
目前的语音辨识系统已达到可接受的程度:手机可用语音声控拨号,汽车的卫星导航系统也能透过语音「说」出路线。
数位声音全面进攻消费性电子
现阶段以DSP来发展消费性电子并未存在高难度的技术障碍,目前所要关注的重心反而是针对整体系统的了解并做最佳化的设计。由于系统的弹性与效率通常无法兼顾,愈有弹性的架构设计,其执行效率就会愈低;反之,执行效率愈高,作业系统通常就愈没有弹性。所以设计者在做技术架构规划时,就必须在弹性度与专业度间取舍并做最佳的判断。另外,由于消费性电子的使用对象是一般大众,在追求经济成本的目标时,除了硬体架构设计外,也要保留软体的修改空间,以软硬体最佳化方式来追求最佳成本。
DPS未来的发展重点将是低耗电量、更快的时脉速度与价格的竞争,尤其在可携式产品的应用上,如何提升效能又同时兼顾耗电量的问题,乃是最需要重视的问题。而在音讯处理方面,也有很大的改进空间,声音合成要创造出更真实、更自然、更丰富的声音;在声音压缩方面,再继续提高压缩比率,以更少的空间储存更多的资讯并保有更真实的声音;在声音辨识方面,希望能做到让机器产生更好的反应,开发出更加友善的使用产品。而噪音抑制技术愈加成熟后,人们也将享受到整体声音环境的提升。
结语
随着数位化进程的加速,未来数位讯号将会取代更多的类比讯号环境,这意谓将有更多的音讯产品采用DSP作设计。例如:扩大机数位化后,在可接受的音质范围内,D类放大器更能达到高效能运作,其它像数位电话、数位广播、数位电视等相关音效设备,也都将促进DSP的蓬勃发展。目前音乐的储存格式早已由CD取代传统的Tape,如今在数位可携式音乐的浪潮推进下,MP3格式大众化的年代已经宣布来临。虽然仍有许多技术问题尚待克服,但声音的数位化显然正在快速前进中,将带给人们生活上更多的便利与享受。 (作者为AT-Chip演算科技行销企划部副理)
|
|
 |
设计一个语音辨识程式,至少要有两方面的知识:了解如何把外界的声音讯号抓到电脑内部处理。相关介绍请见「何谓语音辨识」一文。 |
|
语音辨识技术应用之发展趋势。你可在「语音辨识及语音合成」一文中得到进一步的介绍。 |
|
手机与 PDA 已能够提供各种不同娱乐功能,而消费者更希望其能够拥有立体声,甚至是 3D 音效。在「手机与PDA之声频系统应用探微」一文为你做了相关的评析。 |
|
|
 |