嵌入型系统中处理器MIPS与周边元件间的频宽差距日渐扩大。系统效能并非完全取决于处理器的速度。虽然较高MIPS效率的处理器可提供更高的系统效能,但周边元件的延迟最终仍会成为系统效能的瓶颈。针对汇流排与元件效能的分析,所得到的结果是处理器与元件效能无法完美配合,让客户必须面对「成本」与「效能」两难取舍的窘境。
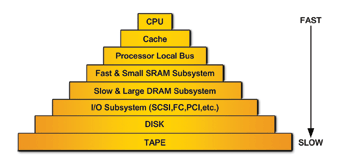
现今的系统是透过多层级子系统所组成,子系统之间的存取时间皆不相同。 (图一)显示一个分层式「金字塔型」的效能架构:由顶层到底层分别表示速度由快到慢的层级。上方的六个子层各代表一套嵌入型系统。由上而下,各层的元件分别为:
- 1. 中央处理器(CPU)
- l2. 快取记忆体 (Cache memory)
- 3. 处理器区域汇流排 (Processor Local Bus; PLB)
- 4. 速度快且体积小的静态随机存取记忆体子系统
- (Static Random Access Memory; SRAM)
- 5. 速度慢且体积大的动态随机存取记忆体子系统
- (Dynamic Random Access Memory; DRAM)
- 6. 输入/输出(Input/Output; I/O)子系统:此种输出/输入的介面可能包括SCSI介面、光纤通道(Fibre Channel; FC)、PCI 介面(Peripheral Component Interconnect; PCI)与其它汇流排或是通讯协定
- 7. 磁碟阵列 (Disk array)- 包括以整合电子式驱动介面 (Integrated Drive Electronics; IDE) 、SCSI或是光纤通道(FC)等介面
- 8. 磁带子系统 (Tape subsystem)
在这个「金字塔式」的架构图中,愈接近底部的子系统,其需要较长的存取时间。例如:32位元中央处理器(CPU)运作速度高达200 MHz(5 ns的周期时间),而IDE磁碟阵列介面硬碟机以每秒33 MB的速度传送资料,在32位元的汇流排中,33 MB/s 等于8.25 MHz 的运作速度(121 ns 周期时间)。因此,32位元CPU比IDE磁碟阵列介面的速度快达24倍。
磁带机需花费数秒的时间将磁带转至磁卷的开头之后才能开始存取资料。而磁带机的资料传输速度从5 MB/s 至15 MB/s不等,而5 MB/s的资料传输速度等于1.25 MHz (32-bit)的传输率;因此200 MHz的CPU比磁带机介面快160倍,又再度证明中央处理器(CPU)与磁碟或磁带储存装置的频宽差距显著。
在嵌入型系统本身,CPU与周边元件之间的速度亦有相当的差距。如图一所示,嵌入型系统中的传输时间随着与CPU之间的距离而递增。以下我们针对一套小型嵌入型电脑系统(small embedded computer system)介绍以上的议题。
嵌入型系统元件选择要领
一般业界接纳的嵌入型系统定义是指一套专为特殊应用所设计的嵌入型系统,例如像光纤通道控制器、磁碟控制器、或是汽车引擎控制器。而非嵌入型的通用系统通常能执行多种不同的应用程式,例如像桌上型PC,能执行文书处理程式、试算表、或是工程设计等类型的软体。本文介绍部份元件之间的互动以及强调各元件之间运算(analyzing)与组合效能上的价值。以下将介绍图一中最上面六层的元件。
中央处理器(CPU) 的选择
现今的CPU配备有各种不同的功能组合。部份的关键功能包括MIPS效能、内建于晶片中的第一阶(L1)快取组态与容量、执行单元的数量、晶片内建暂存器的数量、区域汇流排介面架构(包括单一分享式指令与资料汇流排的Von Neumann架构,以及拥有独立指令与资料汇流排的Harvard架构)。
快取组态 (Cache Configurations)
取舍因素:SRAM 价格 v.s.快取效能
快取是容量小、速度快的记忆体用来改进记忆体的平均回应速度。为了维持全速效能,CPU必须能够使用内部快取所提供的指令与资料,借以避免必须存取外部记忆体。 L1快取是系统中速度最快的记忆体,通常内建于CPU内部。有些CPU内部没有内建快取,而是将外部高速静态随机存取记忆体(SRAM)与CPU紧密配置在一起,其运作速度接近CPU本身的速度。此外高速SRAM相当昂贵,因此通常必须分析价格与效能,并针对特定系统选择最具成本效益的快取组态。
不幸的是,快取的容量通常不足以容纳整组执行程式码,因此CPU必须定期向外界存取指令与资料。当CPU被迫存取外部资料时,PLB的速度(例如,CPU与其它元件互传资料时所经过的通道)与主记忆体子系统的效能将成为关键的系统瓶颈。
处理器区域汇流排 (Processor Local Bus)
取舍因素:PLB 速度 v.s. 频宽
PLB是直接串连至CPU的资料通道,也是系统中最快的平行汇流排。在PLB与所有区域周边元件连线时,CPU在全速运行的情形下是最理想的状况。然而,CPU外部的高速汇流排受到许多因素所限制。印刷电路板(PCB)配置因为线路数量庞大(32至64资料位元,约等于位址位元的数量)导致其结构极为复杂。业界用来支援高频讯号路由器的技术会增加机板开发流程的时间与费用,另外串音(Crosstalk)与非预期的振幅偏移是众多讯号完整性问题中与复杂线路配置有关的因素。这些因素通常导致需在PLB的速度与频宽上做取舍。
主计忆体系统
取舍因素:SDRAM v.s. DDR SDRAM v.s. DDR SDRAM
系统流量受到记忆体向高速CPU传送资料的速度有所影响。在嵌入型系统中,L1快取旁的记忆体通道(bank)通常就是主记忆体通道。记忆体技术持续演进,目标就是希望能跟上高速处理器的脚步。目前SRAM是速度更快、密度更低,且比DRAM更昂贵的记忆体。因此,SRAM的应用一般仅限于快取应用系统。而主记忆体通则常采用DRAM。
嵌入型系统记忆体已逐渐从快速页面模式(Fast Page Mode;FPM)与Extended Data Out (EDO) DRAM 转移至Single Data Rate(SDR)、同步DRAM (SDRAM) 以及Double Data Rate (DDR) SDRAM。最近发展的新趋势则是Quad Data Rate以及其它创新的记忆体技术。
I/O 子系统互动
电脑系统并非完全独立,必须与其它系统透过I/O控制器相互传送资料,因此CPU必须进行额外的晶片外部(off-chip)存取动作。 I/O周边元件通常是透过一组PLB进行存取,PLB则串连至其它标准汇流排桥接元件。 I/O控制器配备一组嵌入型介面,经由这套介面串连至标准汇流排,而不是透过一套特定的CPU汇流排介面。因此处理器的区域汇流排必须运用一组桥接元件转译成标准汇流排的格式。
I/O 周边元件的运作亦需要存取PLB上的元件(透过桥接器),若CPU需要存取PLB而I/O控制器也正在使用PLB时,CPU就必须等待,同时亦可能延迟指令的执行。 I/O控制器通常负责串连至嵌入型系统以外的装置,例如像位于图一中较低层的磁碟阵列以及磁带子系统。
软体
软体以虚拟化嵌入型系统最佳化与模式(pattern)的方式影响其效能表现(例如,精简性 - 更小、更紧密的程式码会耗用较少的记忆体)。模式(pattern)则是表示系统会执行图一中那些架构部份以及耗用的时间比率。
软体的影响关键在于CPU能否充份运用所有MIPS效能。若程式码能配合CPU晶片内部的快取容量,则CPU就能在MIPS全速下运作,在这种情况下,CPU的MIPS效能就成为最重要的因素。但大多数的状况,所有程式码并不能完全置入快取记忆体。以下我们将针对一套小型系统的记忆体选择进行探讨。
嵌入型系统范例
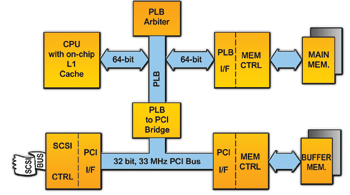
(图二)显示一个含有晶片内快取的小型嵌入型系统图。现代的嵌入型CPU内建的快取容量从8KB至32KB不等。底层的程式码核心若落在8KB的范围内,则对效能的助益就较不显著,但RTOS即时作业系统的核心就可能耗用64KB至数megabytes的记忆体。应用软体相关的程式码则不包括在这些数字中。
典型的8KB核心会填入8KB的快取。在启动后,当核心被执行时就会逐步被置入快取中。当核心完成系统启动作业时应用软体的程式码就会被启动,而快取也会被填满。若程式码呼叫外常态形式(routine),核心会被快取置出,将空间腾出给应用程式使用,反之亦然。
快取置换(Cache thrashing )会发生在当某个经常被使用的位址被另一个经常使用的位址所取代之时。每当CPU在快取中找不到所需的资料时,就必须以较低的主记忆体速度执行主记忆体作业周期。因此,CPU的效能就会因等待快取资料而减缓。容量较大的快取能储存更多的资料,减低CPU存取外部记忆体的频率。简单的说,快取容量愈大、CPU的效能就愈高,但更大的快取须耗费更多的成本。
主记忆体
有关主记忆体的第一个选择就是决定使用静态随机存取记忆体(SRAM)或是动态随机存取记忆体(DRAM)。同步静态随机存取记忆体( Synchronous SRAM)相当快速且昂贵。一般而言,系统需要的记忆体数量相当大,因此SRAM会因成本过高而不适用。此外,包括消耗功率以及较低的密度(比DRAM耗用更多的电路板空间),也是SRAM不适用为主记忆体的原因。在众多理由之下,DRAM成为许多嵌入型系统设计的最佳记忆体技术。
SRAM 主记忆体
在决定使用DRAM之后,设计人员面临许多DRAM选项:SDR、DDR、或其它较少见的技术。同步DRAM(SDRAM)元件有单资料传输率(Single Data Rate; SDR)SDRAM以及双倍资料传输率(Double Date Rate; DDR)SDRAM两种类型。在DDR SDRAM中,新资料的供应发生于时脉的上升(rising)与下落(falling)两端。 SDR SDRAM提供是143 MHz的时脉,有些DDR元件支援这个时脉,同时能在286 MHz的速度下传输资料。
记忆体效能
DRAMS有分页开启、行位址控制器延迟时间(Column-address strobe; CAS)、以及随后产生的列位置信号延迟(Row-addess strobe; RAS)等问题,其中的CAS会降低有效资料传输率,同时记忆体控制器也会增加延迟的程度。
SDR SDRAM
现代的SDR SDRAM的时脉通常达143MHz,须耗用3个时脉延迟来开启一个分页,来进行读或写的作业。在相容的分页中(例如RAS延迟已经产生),会产生另一个 3 CAS的延迟(CAS Latency of Three)。这代表快冲(burst)资料的传输率达143 MHz,但快冲的第一组资料会延迟三个时脉周期(在接收读或写指令之后)。在同一分页的一组4字元快冲,则需6个时脉周期让平均资料传输率从143 megabits (Mb/s)降低至(对于一组x8 元件) 95 Mb/s,若分页产生变动则会加入一组3时脉的分页而延迟开启。
DDR SDRAM
为提升效能,主记忆体通道(bank)可从SDR转变为DDR SDRAM。这些元件须经过约3个时脉延迟才能开启一个分页进行读或写的作业。一个典型的 "8M x 8 M" - 等级7的元件,CAS延迟为2.5,时脉为143MHz。这组DDR元件在143MHz时脉的两个端点都能传输资料,故其快冲传输率为286 Mb/s。前端(up-front)的2.5 CAS延迟让传输率比前者较低。在相同的分页中,对于一组4字元的快冲作业,需耗用9个时脉周期,让平均资料传输率从286 Mb/s 降低至127 Mb/s 。若分页产生变动,就会增加一组为期3个时脉的分页启始延迟。
结论
系统效能与应用种类有直接的关系。在本文中,我们分析一套嵌入型系统范例,显示CPU时脉在经历不同的频率范围时,系统效能在多处会上扬至高峰点。 PLB与记忆体子系统的各种特性会在不同的CPU速度产生不明显的效能高峰。这些结果证明极高速且昂贵的处理器,其MIPS效能无法永远充份运用。妥善搭配处理器与元件的效能,能在成本与效能之间取得最佳的平衡点。
(作者任职于Xilinx)